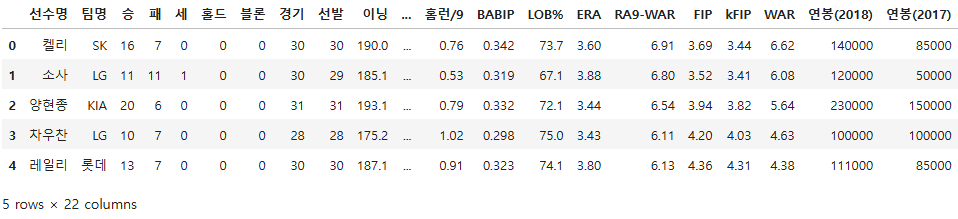
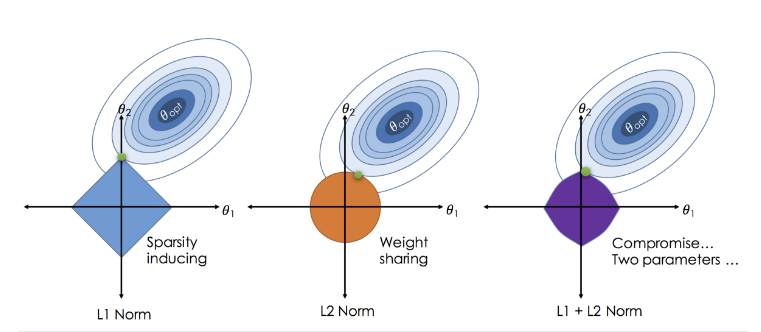
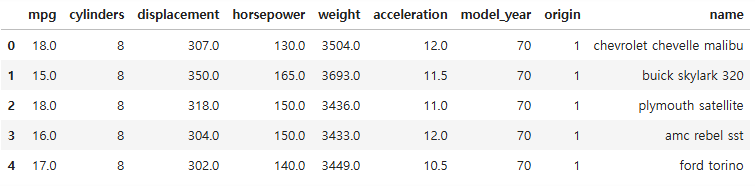
프로 야구선수 연봉 예측 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.preprocessing import StandardScaler, OneHotEncoder # 사이킷런에서도 원핫인코딩을 제공해줌from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_absolute_errorfrom statsmodels.stats.outliers_influence import variance_infl..