728x90
파이프라인 구축
from sklearn.svm import SVC
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
데이터 준비
cancer = load_breast_cancer()
type(cancer)
sklearn.utils._bunch.Bunch
# 독립변수
cancer["data"].shape
(569, 30)
cancer["data"][0]
array([1.799e+01, 1.038e+01, 1.228e+02, 1.001e+03, 1.184e-01, 2.776e-01,
3.001e-01, 1.471e-01, 2.419e-01, 7.871e-02, 1.095e+00, 9.053e-01,
8.589e+00, 1.534e+02, 6.399e-03, 4.904e-02, 5.373e-02, 1.587e-02,
3.003e-02, 6.193e-03, 2.538e+01, 1.733e+01, 1.846e+02, 2.019e+03,
1.622e-01, 6.656e-01, 7.119e-01, 2.654e-01, 4.601e-01, 1.189e-01])- 데이터의 모양 확인
- 변수가 30개임
# 종속변수
cancer["target"]
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0,
1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0,
1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0,
0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1,
1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0,
1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0,
0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,
1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1,
1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1])
# 독립변수명
cancer["feature_names"], len(cancer["feature_names"])
(array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23'),
30)
# 종속변수 범주명
cancer["target_names"]
array(['malignant', 'benign'], dtype='<U9')
df = pd.DataFrame(cancer["data"], columns = cancer["feature_names"])
df["target"] = cancer["target"]
df.head()

데이터 분할
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size = 0.25,
stratify = cancer.target, random_state = 26)
x_train.shape, x_test.shape
((426, 30), (143, 30))
모델 학습
clf = SVC()
clf.fit(x_train, y_train)
pred = clf.predict(x_test)
accuracy_score(y_test, pred)
0.9020979020979021
최적화
mm = MinMaxScaler()
scaled_train = mm.fit_transform(x_train)
scaled_test = mm.transform(x_test)
clf2 = SVC()
clf2.fit(scaled_train, y_train)

clf2.score(scaled_test, y_test)
0.965034965034965
하이퍼 파라미터 튜닝
- 머신러닝 모형이 완성되고 나서 매개변수 최적화를 통해서 예측 성능을 더 극대화
param_grid = {"C" : [0.0001, 0.001, 0.1, 1, 10, 100, 1000],
"gamma": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]}
gs = GridSearchCV(SVC(), param_grid = param_grid, n_jobs = -1)
gs.fit(scaled_train, y_train)
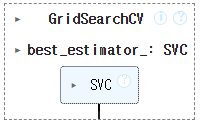
gs.best_score_
0.9765526675786594
gs.best_params_
{'C': 10, 'gamma': 0.1}
gs.score(scaled_test, y_test)
0.965034965034965
파이프라인 구축
- 여러 알고리즘을 비교
- 전체 공정을 시퀀스로 연결하여 구성
파이프라인 구축 방법
- ver1: 표준 벙법
- 작업 순서를 나열하고, 이름을 각각 부여
- 후보가 유력한 알고리즘과 전처리기를 배치
pipe = Pipeline([("scaler", MinMaxScaler()),
("classifier", SVC())])
pipe

- ver2: 간소화 방법
- 이름을 부여하지 않고 자동으로 부여됨

파이프라인 적용
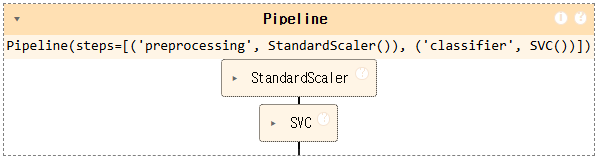
pipe = Pipeline([("preprocessing", StandardScaler()),
("classifier", SVC())])
pipe
# 하이퍼파라미터 정의
param_grid = [
{
"classifier" : [SVC()],
"preprocessing" : [StandardScaler(), MinMaxScaler()],
# 이름_파라미터명 => 해당 알고리즘에 적용되는 파라미터
"classifier__C" : [0.001, 0.01, 0.1, 1, 10, 100],
"classifier__gamma" : [0.001, 0.01, 0.1, 1, 10, 100]
},
{
"classifier": [RandomForestClassifier(random_state = 26)],
"preprocessing" : [None],
"classifier__max_features" : [1, 2, 3]
}
]
# 결합(파이프라인, 하이퍼파라미터 튜닝)
gs = GridSearchCV(pipe, param_grid, n_jobs = -1)
gs.fit(x_train, y_train)
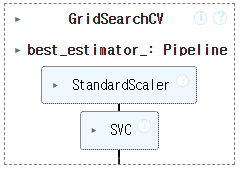
gs.best_score_
0.9765526675786594
gs.best_params_
{'classifier': SVC(),
'classifier__C': 10,
'classifier__gamma': 0.01,
'preprocessing': StandardScaler()}
gs.score(x_test, y_test)
0.958041958041958'08_ML(Machine_Learning)' 카테고리의 다른 글
| 26_군집 알고리즘(k-means) (0) | 2025.04.11 |
|---|---|
| 25_군집 알고리즘(비지도 학습)-과일 사진 레이블 없이 분류 (0) | 2025.04.11 |
| 23_서포트 벡터 머신 (0) | 2025.04.11 |
| 22_랜덤포레스트_문제(상한 개사료) (0) | 2025.04.11 |
| 21_트리 앙상블 (0) | 2025.04.10 |