728x90
트리 앙상블
앙상블
- 여러 머신러닝 모델을 결합하여 더 좋은 모델을 얻는 방법
- 앙상블의 종류
- 보팅
- 배깅
- 부스팅 등
보팅(Voting)
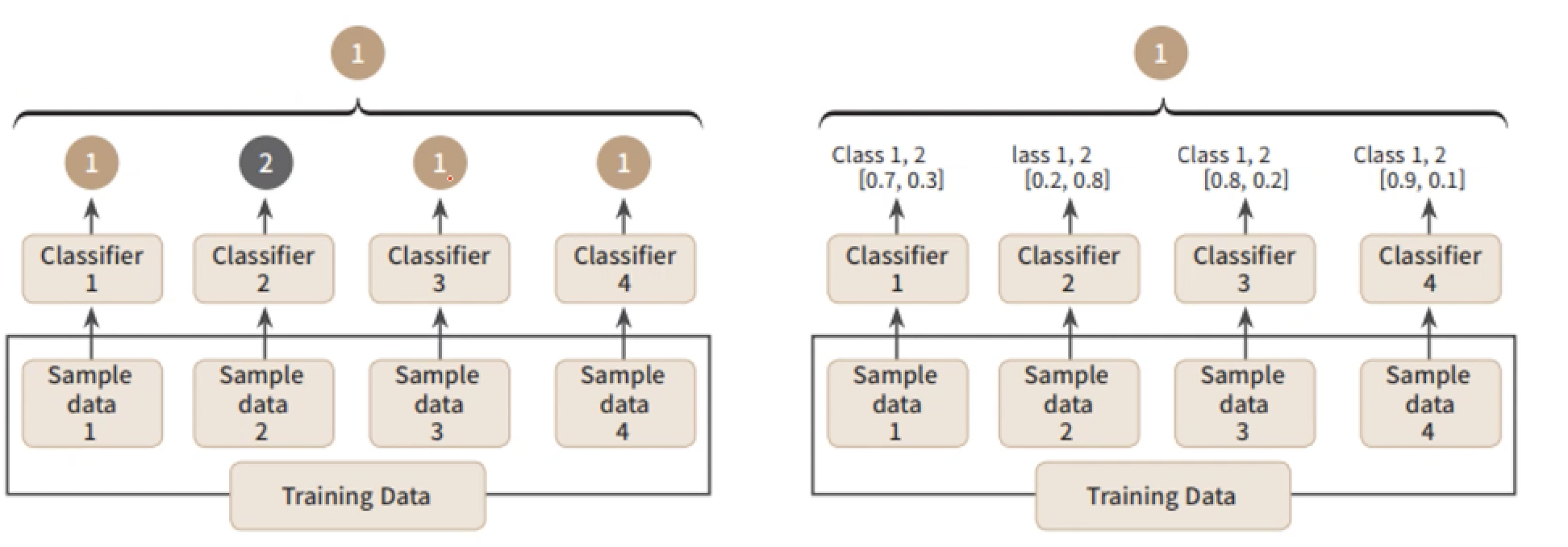
- 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정
- 종류
- 하드 보팅(Hard Voting)
- 다수의 분류기가 예측한 결과값을 최종 결과로 선정
- 소프트 보팅(Soft Voting)
- 모든 분류기가 예측한 결정 확률의 평균이 가장 높은 결과값을 최종 결과로 선정
- 하드 보팅(Hard Voting)
배깅(Bagging)

# 복원추출
# 각각의 데이터셋을 가지고 학습한 모델들
- 데이터 샘플링(Bootstrap)을 통해 모델을 학습시키고 결과를 집계하는 방법
- Bootstrap
- 데이터가 조금씩은 편향되도록 샘플링하는 기법
- 분산이 높은 모델의 과대적합 위험을 줄이는 효과가 있음
- Bootstrap
- 모두 같은 유형의 알고리즘 기반의 분류기를 사용
- 데이터 분할 시 중복을 허용
- 예시: 랜덤포레스트(RandomForest)
- 과대적합되기 쉬운 의사결정나무의 과대적합을 줄여 성능을 높일 수 있음
부스팅(Boosting)
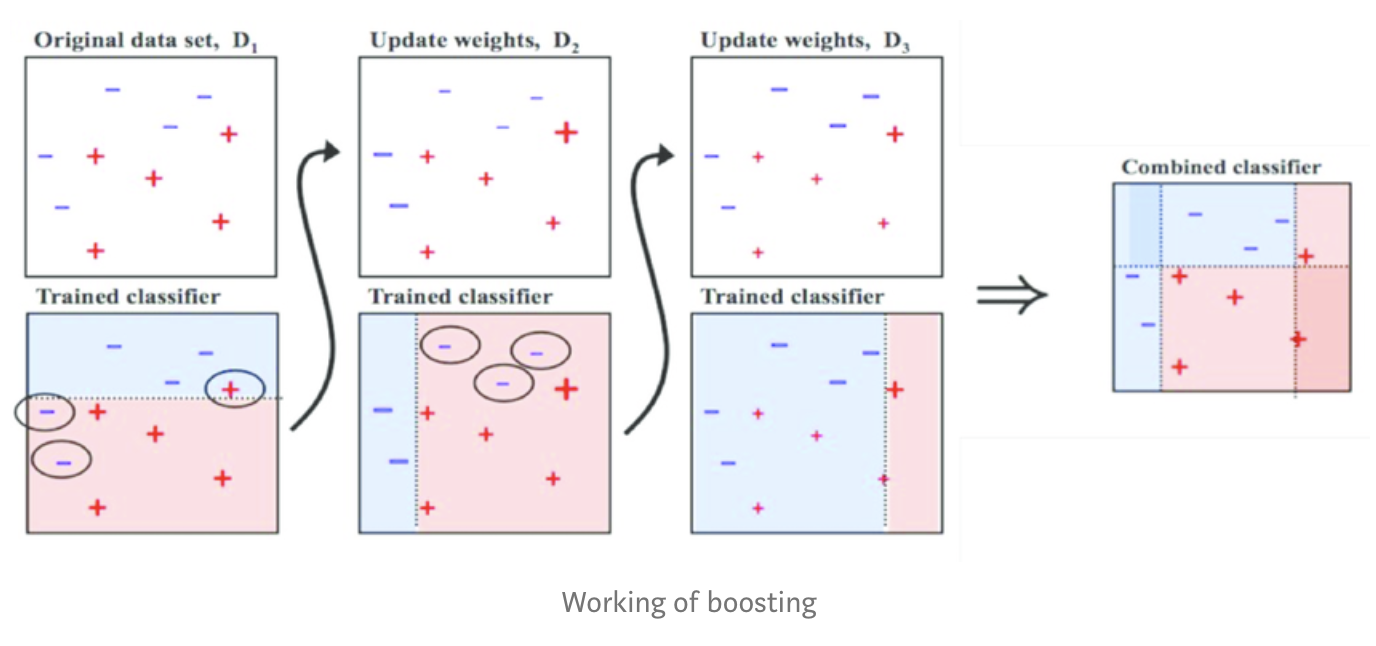
# 부스팅 -> 순차적으로 학습해야함
- 여러 개의 분류기가 순차적으로 학습을 수행
- 이전 분류기의 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측을 진행
- 계속하여 분류기에게 가중치를 부스팅하며 학습을 진행하기 때문에 부스팅 방식이라고 불림
- 일반적으로 부스팅 방식이 배깅에 비해 성능이 좋지만 속도가 느리고 과적합이 발생할 가능성이 더 높음
- 예시: XGBoost, LightGBM
랜덤포레스트(가장 기본)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, cross_validate
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
df = pd.read_csv('./data/wine.csv')
df.head()

x = df.drop("class", axis = 1)
y = df["class"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, stratify = y, random_state = 26)
# 사이킷런의 랜덤포레스트는 기본적으로 100개의 결정 트리를 사용함
rf = RandomForestClassifier(n_jobs = -1, random_state = 26)
# return_train_score: 교차 검증 시 훈련 세트에 대한 점수도 함께 반환(원래는 검증 데이터에 대한 점수만 반환)
scores = cross_validate(rf, x_train, y_train, return_train_score = True, n_jobs = -1)
print(np.mean(scores["train_score"]), np.mean(scores["test_score"]), np.mean(scores["fit_time"]))
0.9979795781335353 0.8926293773598875 0.2214503765106201
- 랜덤포레스트는 의사결정나무의 앙상블이기 때문에 의사결정나무에서 제공하는 주요 매개변수는 모두 제공함
- 특성 중요도 계산도 가능
- 랜덤포레스트의 특성 중요도는 각 의사결정나무의 특성 중요도를 취합
- 특성 중요도 계산도 가능
rf.fit(x_train, y_train)

rf.feature_importances_
array([0.23820619, 0.50152526, 0.26026855])
- 의사결정나무에 비해 두 번째 특성인 sugar의 중요도가 감소하고 alcohol과 pH의 중요도가 상승함
- 랜덤포레스트는 하나의 특성에 과도하게 집중되지 않고 더 많은 특성이 훈련에 기여할 기회를 얻음
- 과대적합이 줄어들고 일반화 성능을 높일 수 있음
rf = RandomForestClassifier(oob_score = True, n_jobs = -1, random_state = 26)
rf.fit(x_train, y_train)
# oob: out of back

rf.oob_score_
# 0.8926293773598875 검증 데이터와 비슷한 수치
0.8974408312487974
- OOB(out of bag)샘플
- 부트스트랩 샘플에 포함되지 않아 훈련에 사용되지 않은 샘플
- oob 샘플을 검증 세트처럼 이용하여 훈련한 결정 트리를 평가할 수 있음
엑스트라 트리
- 랜덤포레스트와 매우 유사함
- 기본적으로 100개의 의사결정나무를 훈련
- 의사결정나무가 제공하는 대부분의 매개변수를 지원
- 랜덤포레스트와의 차이점
- 부트스트랩 샘플을 사용하지 않음
- 전체 훈련 세트를 사용함
- 노드를 분할할 때 가장 좋은 분할을 찾는 것이 아니라 무작위로 분할함
- 하나의 의사결정나무에서 특성을 무작위로 분할한다면 성능이 낮아짐
- 하지만 많은 트리를 앙상블하기 때문에 과대적합을 방지하고 검증 세트 점수를 높이는 효과가 나타남
- 부트스트랩 샘플을 사용하지 않음
et = ExtraTreesClassifier(n_jobs = -1, random_state = 26)
scores = cross_validate(et, x_train, y_train, return_train_score = True, n_jobs = -1)
print(np.mean(scores["train_score"]), np.mean(scores["test_score"]), np.mean(scores["fit_time"]))
0.9980276781816354 0.8951328940549346 0.18139023780822755
- 예제에서는 독립변수가 많지 않아서 랜덤포레스트와 차이가 크지 않음
- 일반적으로 엑스트라트리가 무작위성이 더 크기 때문에 랜덤포레스트보다 더 많은 트리를 훈련해야함
- 하지만 랜덤하게 노드를 분할하기 때문에 계산 속도가 빠름
# 엑스트라 트리도 특성 중요도를 제공함
et.fit(x_train, y_train)
print(et.feature_importances_)
[0.18806788 0.52480397 0.28712815]
그레디언트 부스팅(gradient boosting)
- 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블하는 기법
- 사이킷런의 GradientBoostingClassifier는 기본적으로 깊이가 3인 결정트리를 100개 사용함
- 깊이가 얕은 결정 트리를 사용하여 과대적합을 방지할 수 있고 높은 일반화 성능을 기대할 수 있음
gb = GradientBoostingClassifier(random_state = 26)
scores = cross_validate(gb, x_train, y_train, return_train_score = True, n_jobs = -1)
print(np.mean(scores["train_score"]), np.mean(scores["test_score"]), np.mean(scores["fit_time"]))
0.8843081027348528 0.8687706374472496 0.24927101135253907
- 그레디언트 부스팅은 결정 트리의 개수를 늘려도 과대적합에 강함
gb = GradientBoostingClassifier(random_state = 26, n_estimators = 500, learning_rate = 0.2)
scores = cross_validate(gb, x_train, y_train, return_train_score = True, n_jobs = -1)
# learning_rate = 0.2 :학습률
print(np.mean(scores["train_score"]), np.mean(scores["test_score"]), np.mean(scores["fit_time"]))
0.9425147380884692 0.8770420892870364 1.2247856616973878
gb.fit(x_train, y_train)

gb.feature_importances_
array([0.1535165 , 0.68318837, 0.16329513])'08_ML(Machine_Learning)' 카테고리의 다른 글
| 23_서포트 벡터 머신 (0) | 2025.04.11 |
|---|---|
| 22_랜덤포레스트_문제(상한 개사료) (0) | 2025.04.11 |
| 20_교차검증_그리드서치 (0) | 2025.04.10 |
| 19_의사 결정 나무 (2) | 2025.04.09 |
| 18_확률적 경사 하강법 (0) | 2025.04.09 |