728x90
KNN회귀
01. 생선 길이로 무게 예측
- 회귀(regression)
- 임의의 어떤 숫자를 예측하는 문제
- 변수들 사이의 상관관계를 분석하는 방법
- KNN회귀
- 분류와 똑같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택
- k개의 샘플의 종속변수 값의 평균을 구함
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
02. 데이터 준비
df = pd.read_csv("./data/Fish.csv")
# 농어 데이터만 사용
df = df.loc[df["Species"] == "Perch", ["Species", "Length2", "Weight"]]
df.head()

plt.figure()
plt.scatter(df["Length2"], df["Weight"])
plt.xlabel("length")
plt.ylabel("weight")
plt.show()

- 길이가 커짐에 따라 무게가 증가하는 경향이 있음
# 75 : 25 로 데이터 분할
x_train, x_test, y_train, y_test = train_test_split(df["Length2"], df["Weight"],
test_size = 0.25, random_state = 23)
# (데이터개수, 속성수) 의 2차원으로 맞춰줘야함
x_train.shape
(42,)
# 독립변수는 2차원 배열이어야 함
x_train.values
array([19.6, 32.8, 16.2, 30. , 21. , 36. , 27.5, 26.5, 25.6, 42. , 22.5,
27.5, 40. , 17.4, 28. , 19. , 40. , 13.7, 44. , 40. , 22. , 39. ,
37. , 8.4, 18. , 22.7, 21. , 15. , 40. , 18.7, 24. , 24.6, 35. ,
25. , 21. , 39. , 27.5, 43. , 20. , 36.5, 34.5, 22.5])
x_train = np.reshape(x_train.values, (-1, 1)) #(데이터 개수, 한줄의 데이터가 몇 개의 특징을 가지고 있는지)
x_train.shape
(42, 1)
x_train[:5]
array([[19.6],
[32.8],
[16.2],
[30. ],
[21. ]])
x_test = np.reshape(x_test.values, (-1, 1))
03. 모델 훈련
knr = KNeighborsRegressor()
knr.fit(x_train, y_train)
04. 모델 평가
- 결정 계수(-무한대~1)
- 계산식
- 1 - ((sum((타깃 - 예측)^2))) / (sum((타깃 - 타깃평균)^2))) ※타깃==정답
- 모델의 설명력을 뜻함
- 1에 가까울수록 모델 성능이 좋음
- 계산식
# score는 분류에서는 정확도, 회귀에서는 결정계수임
knr.score(x_test, y_test)
0.9885144748807311
- mean_absolute_error
- 타깃과 예측의 절댓값 오차를 평균하여 반환
# 테스트 세트에 대한 예측
pred = knr.predict(x_test)
pred
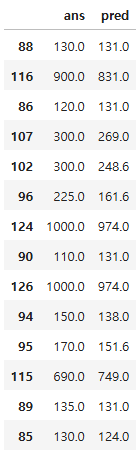
array([131. , 831. , 131. , 269. , 248.6, 161.6, 974. , 131. , 974. ,
138. , 151.6, 749. , 131. , 124. ])
# 테스트 세트에 대한 평균 절댓값 오차를 계산
mae = mean_absolute_error(y_test, pred)
mae
28.514285714285716
pd.DataFrame({"ans" : y_test, "pred" : pred})

max(x_train)
array([44.])
knr.predict([[50]])
array([974.])
knr.predict([[60]])
array([974.])
# 훈련데이터에 있는 최댓값이 1100이므로, 1100보다 높은 데이터는 계산할 수 없음
max(y_train)
1100.0
# 50cm 농어의 이웃 찾기
dist, idx = knr.kneighbors([[50]])
plt.figure()
plt.scatter(x_train, y_train)
plt.scatter(x_train[idx], y_train.iloc[idx.flatten()], marker = "D")
plt.scatter(50, 974, marker = "^")
plt.xlabel("length")
plt.ylabel("weight")
plt.show()

728x90
'08_ML(Machine_Learning)' 카테고리의 다른 글
| 07_KNN구현(Numpy(넘파이)) (0) | 2025.04.04 |
|---|---|
| 06_KNN 심화 (0) | 2025.04.04 |
| 04_KNN_타이타닉 분류 (0) | 2025.04.02 |
| 03_데이터 전처리 (0) | 2025.04.02 |
| 02_KNN 이진분류 (0) | 2025.04.02 |