728x90
KNN 타이타닉 분류
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report
01. 데이터 준비
df = sns.load_dataset("titanic")
df.head()
02. 데이터 탐색
df.shape
(891, 15)
df.dtypes
survived int64
pclass int64
sex object
age float64
sibsp int64
parch int64
fare float64
embarked object
class category
who object
adult_male bool
deck category
embark_town object
alive object
alone bool
dtype: object
df.isna().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
# 결측치가 많은 deck열은 삭제, embarked와 내용이 겹치는 embark_town열을 삭제
rdf = df.drop(["deck", "embark_town"], axis = 1)
rdf.columns
Index(['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare',
'embarked', 'class', 'who', 'adult_male', 'alive', 'alone'],
dtype='object')
# age 열에 결측치가 있는 모든 행을 삭제(177개 행)
rdf = df.dropna(subset = ["age"], axis = 0)
len(rdf), len(rdf)
(714, 714)
891 - 714
177
rdf["embarked"].unique()
array(['S', 'C', 'Q', nan], dtype=object)
# embarked 열의 NaN 값을 승선도시 중에서 가장 많이 출현한 값(최빈값)으로 치환하기
most_freq = rdf["embarked"].value_counts().idxmax()
most_freq
'S'
rdf.describe(include = "all")
rdf["embarked"] = rdf["embarked"].fillna(most_freq)
rdf.isna().sum()
survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
who 0
adult_male 0
deck 530
embark_town 2
alive 0
alone 0
dtype: int64
# 분석에 사용할 속성을 선택
rdf.head()
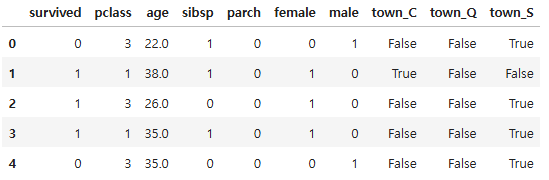
ndf = rdf[["survived", "pclass", "sex", "age", "sibsp", "parch", "embarked"]]
ndf.head()
# 원핫인코딩 - 범주형 데이터를 인식할 수 있도록 숫자형으로 변환
onehot_sex = pd.get_dummies(ndf["sex"], dtype = int)
onehot_sex.head()
ndf = pd.concat([ndf, onehot_sex], axis = 1)
ndf.head()
# 승선도시 원핫인코딩
onehot_embarked = pd.get_dummies(ndf["embarked"], prefix = "town")
onehot_embarked.head()
ndf = pd.concat([ndf, onehot_embarked], axis = 1)
ndf.head()
ndf = ndf.drop(["sex", "embarked"], axis = 1)
ndf.head()
03. 데이터셋 분할 - 훈련/테스트
# 변수 선택
x = ndf.drop("survived", axis = 1)
y = ndf["survived"]
# 7 : 3 분할
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, stratify = y, random_state = 23)
len(x_train), len(x_test)
(499, 215)
04. 모델 학습
# 가장 가까운 객체
np.sqrt(len(x_train))
22.338307903688676
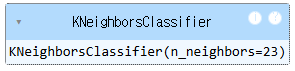
# KNN 분류 모형 객체 생성(k = 23 으로 설정)
knn = KNeighborsClassifier(n_neighbors = 23)
# 모델 학습
knn.fit(x_train, y_train)
# test data 예측
y_pred = knn.predict(x_test)
pd.DataFrame({"ans" : y_test, "pred" : y_pred})

05. 모델 평가
# 혼동 행렬
knn_matrix = confusion_matrix(y_test, y_pred)
오차 행렬
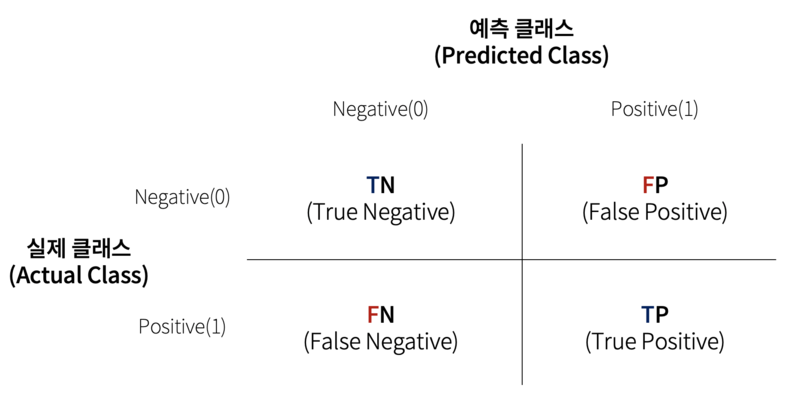
- 이진 분류에서 성능 지표로 잘 활용됨
- 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표
- 이진 분류의 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표
# 0인 레이블을 0이라 한 경우, 0인 레이블을 1이라 한 경우
# 1인 레이블을 0이라 한 경우, 1인 레이블을 1이라 한 경우
print(knn_matrix)
[[118 10]
[ 48 39]]
knn_report = classification_report(y_test, y_pred)
print(knn_report)
precision recall f1-score support
0 0.71 0.92 0.80 128
1 0.80 0.45 0.57 87
accuracy 0.73 215
macro avg 0.75 0.69 0.69 215
weighted avg 0.75 0.73 0.71 215
- 정확도
- 예측 결과와 실제 값이 동일한 건수 / 전체 데이터 수
- (TN + TP) / (TN + FP + FN + TP)
- precision(정밀도)
- 양성으로 예측한 데이터 중 실제로 양성인 데이터의 비율
- TP / (FP + TP)
- 정밀도가 더 중요한 지표인 경우는 양성으로 분류된 데이터가 실제로는 양성이 아니라면 업무상 큰 영향이 발생하는 경우
- 예) 스팸메일 판단 모델: 일반 메일을 스팸메일로 잘못 분류하면 메일을 아예 받지 못할 수 있어 업무에 차질이 생김
- recall(재현율, 민감도)
- 실제 양성인 데이터 중 양성으로 예측한 비율
- TP / (FN + TP)
- 재현율이 중요 지표인 경우는 실제 양성 데이터를 음성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
- 예) 암 판단 모델: 암환자를 음성으로 잘못 판단한다면 생명을 앗아갈 정도로 심각한 문제이기 때문
- specificity(특이도)
- 실제 음성인 데이터 중 음성으로 예측한 비율
- TN / (TN + TP)
- 코로나 검사키트의 경우
- 민감도 90% 이상
- 실제 양성인 사람이 코로나 검사를 하면 양성으로 예측될 확률 90% 이상
- 특이도 99% 이상
- 실제 음성인 사람이 코로나 검사를 하면 음성으로 예측될 확률 99% 이상
- 민감도 90% 이상
06. 모델 고도화
y.value_counts()
survived
0 424
1 290
Name: count, dtype: int64
# 스케일링
ss = StandardScaler()
scaled_train = ss.fit_transform(x_train)
scaled_test = ss.transform(x_test)
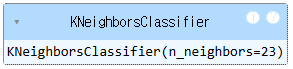
knn = KNeighborsClassifier(n_neighbors = 23)
knn.fit(scaled_train, y_train)
y_pred = knn.predict(scaled_test)
pd.DataFrame({"ans" : y_test, "pred" : y_pred})

knn_matrix = confusion_matrix(y_test, y_pred)
print(knn_matrix)
[[115 13]
[ 33 54]]
knn_report = classification_report(y_test, y_pred)
print(knn_report)
precision recall f1-score support
0 0.78 0.90 0.83 128
1 0.81 0.62 0.70 87
accuracy 0.79 215
macro avg 0.79 0.76 0.77 215
weighted avg 0.79 0.79 0.78 215
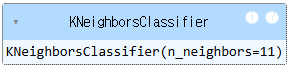
# K값을 11로 수정
knn = KNeighborsClassifier(n_neighbors = 11)
knn.fit(scaled_train, y_train)
y_pred = knn.predict(scaled_test)
knn_report = classification_report(y_test, y_pred)
print(knn_report)
precision recall f1-score support
0 0.76 0.88 0.82 128
1 0.78 0.60 0.68 87
accuracy 0.77 215
macro avg 0.77 0.74 0.75 215
weighted avg 0.77 0.77 0.76 215728x90
'08_ML(Machine_Learning)' 카테고리의 다른 글
| 06_KNN 심화 (0) | 2025.04.04 |
|---|---|
| 05_KNN회귀 (0) | 2025.04.04 |
| 03_데이터 전처리 (0) | 2025.04.02 |
| 02_KNN 이진분류 (0) | 2025.04.02 |
| 01. 머신러닝 기본 이론 (2) | 2025.04.02 |