728x90
KNN 이진분류
01. 생선 분류
- 수산물 전문 물류 센터에서 신입 직원들이 생선 이름을 외우지 못해 작업의 효율성이 현저히 떨어지는 일이 잦음
- 이 물류 센터에서는 주로 생선의 길이와 무게로 생선을 분류
- 판매하는 생선은 도미, 잉어, 대구, 청돔, 농어, 민물꼬치고기, 빙어
02. 이진 분류(binary classification)
- 분류(classification): 여러 개의 범주(클래스) 중 하나를 구별해 내는 것
- 이진 분류: 2개의 범주 중 하나를 고류는 분류
- 도미인가 빙어인가
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder # 사이킷런의 전처리기 -> 카테고리값을 코드값으로
from sklearn.neighbors import KNeighborsClassifier # 이웃 알고리즘
03. 데이터 준비
df = pd.read_csv("./data/Fish.csv")
df.head()
df.shape # 보통 10만개정도의 데이터가 머신러닝에 쓰이지만 예제의 데이터는 159개
(159, 7)
df.dtypes
Species object
Weight float64
Length1 float64
Length2 float64
Length3 float64
Height float64
Width float64
dtype: object
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 159 entries, 0 to 158
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Species 159 non-null object
1 Weight 159 non-null float64
2 Length1 159 non-null float64
3 Length2 159 non-null float64
4 Length3 159 non-null float64
5 Height 159 non-null float64
6 Width 159 non-null float64
dtypes: float64(6), object(1)
memory usage: 8.8+ KB
df["Species"].unique()
array(['Bream', 'Roach', 'Whitefish', 'Parkki', 'Perch', 'Pike', 'Smelt'],
dtype=object)
# 이번 예제에서는 도미와 빙어에 대한 데이터 중 종, 무게, 길이 피처만 사용
df = df.loc[df["Species"].isin(["Bream", "Smelt"]), ["Species", "Weight", "Length2"]]
df.head()
df.shape
(49, 3)
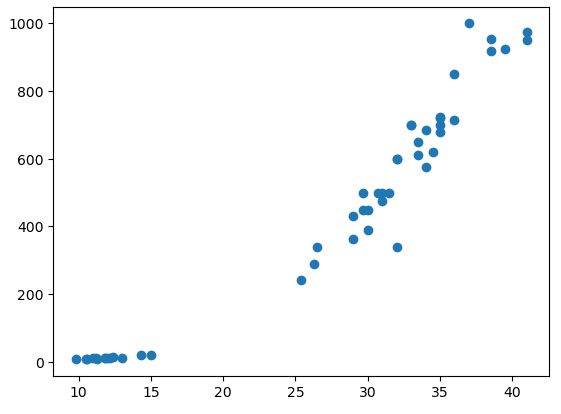
plt.figure()
plt.scatter(data = df, x = "Length2", y = "Weight")
plt.show()
groups = df.groupby("Species")
plt.figure()
for name, group in groups:
plt.scatter(group["Length2"], group["Weight"], label = name)
plt.legend()
plt.xlabel("Length")
plt.ylabel("Weight")
plt.show()
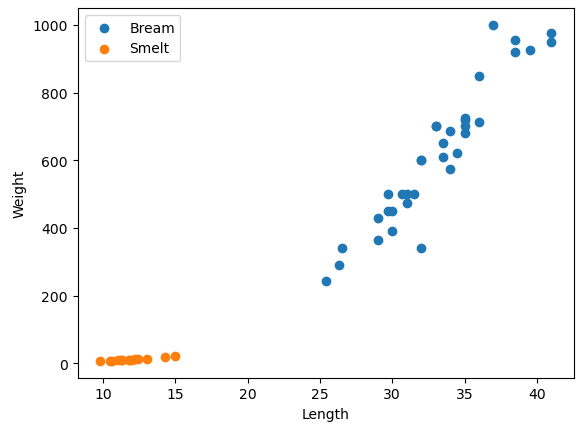
- 도미의 길이가 길수록 무게가 무거워지는 경향이 있음
- 빙어는 상대적으로 무게가 영향을 덜 받는 것처럼 보이지만 데이터의 분포가 일직선에 가까워 선형적임
04. 레이블 인코딩
- 컴퓨터는 문자의 의미를 직접 이해하지 못함
- 따라서 도미와 빙어를 숫자 0과 1로 표현
le = LabelEncoder()
df["label"] = le.fit_transform(df["Species"])
df.head()
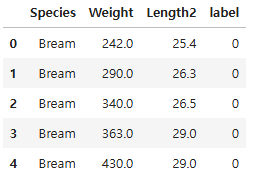
df["Species"].value_counts()
Species
Bream 35
Smelt 14
Name: count, dtype: int64
df["label"].value_counts()
label
0 35
1 14
Name: count, dtype: int64
# 인코딩 클래스 확인
le.classes_
array(['Bream', 'Smelt'], dtype=object)
# 인코딩된 값을 다시 디코딩
le.inverse_transform(df["label"][:5])
array(['Bream', 'Bream', 'Bream', 'Bream', 'Bream'], dtype=object)
05. 모델 훈련
K-Nearest Neighbor
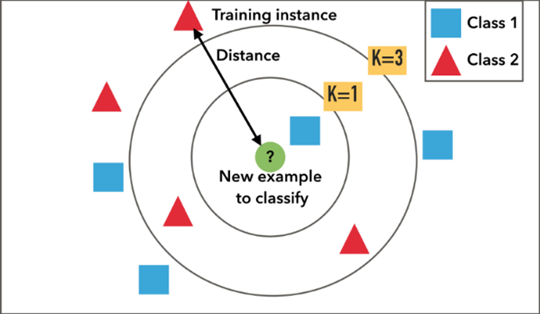
- 기존 데이터 중 가장 유사한 k개의 데이터를 이용해서 새로운 데이터를 예측
- 특징
- 최고 인접 다수결
- 기존 데이터 중 가장 유사한 k개의 데이터를 측정하여 분류
- Lazy learning 기법
- 새로운 입력 값이 들어온 후 분류 시작
- 데이터셋을 저장만 하고 일반화된 모델을 능동적으로 만들지 않음
- 단순 유연성
- 모형이 단순하며 파라미터의 가정이 거의 없음
- 최고 인접 다수결
- 장점
- 학습이 간단
- 훈련 데이터의 크기가 클수록 정확해짐
- 모형이 단순하고 쉽게 구현할 수 있음
- 단점
- k값 선정에 따라 성능이 좌우됨(동률이 될 가능성 때문에 k값은 일반적으로 홀수로 설정)
- 높은 자원 요구량
- 데이터셋 전체를 메모리에 기억
- 계산 복잡성
- 모든 데이터와의 거리 측정 수행이 필요
# KNN 분류기 모델 객체 생성
knn = KNeighborsClassifier()
# 모델 훈련
knn.fit(df[["Length2", "Weight"]], df["label"])
knn.score(df[["Length2", "Weight"]], df["label"]) # score(예측값(평가를 수행할 데이터), 정답값)
1.0
- 정확도
- 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값
- 0 ~ 1사이의 값으로 출력
- 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
groups = df.groupby("Species")
plt.figure()
for name, group in groups:
plt.scatter(group["Length2"], group["Weight"], label = name)
plt.scatter(30, 600, c = "g", marker = "^", label = "predict") # (30, 600)의 물고기가 어떤 물고기인지 예측
plt.legend()
plt.xlabel("Length")
plt.ylabel("Weight")
plt.show()
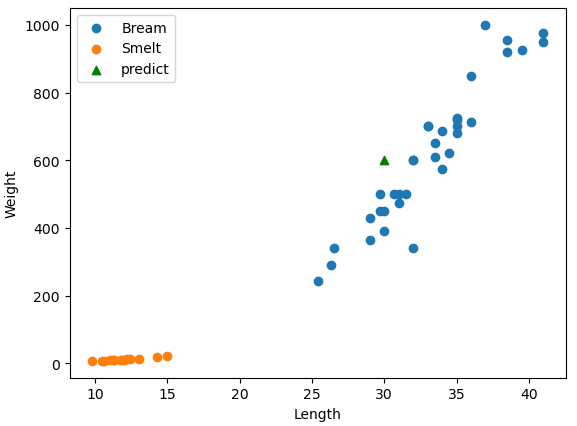
# 길이 30, 무게 600의 생선에 대한 예측
knn.predict([[30, 600]])
array([0])
# 레이블인코더로 예측값 디코딩
le.inverse_transform([0])
array(['Bream'], dtype=object)- 모든 데이터로 학습을 하면 정답을 잘 맞히는 것이 당연하기 때문에 일반화할 수 있는 좋은 모델인지를 평가할 평가지표가 없음
728x90
'08_ML(Machine_Learning)' 카테고리의 다른 글
| 06_KNN 심화 (0) | 2025.04.04 |
|---|---|
| 05_KNN회귀 (0) | 2025.04.04 |
| 04_KNN_타이타닉 분류 (0) | 2025.04.02 |
| 03_데이터 전처리 (0) | 2025.04.02 |
| 01. 머신러닝 기본 이론 (2) | 2025.04.02 |