728x90
# 유튜브랭킹>전체순위
# https://youtube-rank.com/
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from urllib.request import urlopen
# Windows용 한글 폰트 오류 해결
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname = font_path).get_name()
rc("font", family = font_name)
url = 'https://youtube-rank.com/board/bbs/board.php?bo_table=youtube'
page = urlopen(url)
soup = BeautifulSoup(page, "lxml")
soup.select("p.category")[0].string.strip()
'[음악/댄스/가수]'
soup.select("td.subject > a")[0].string.strip()
'BLACKPINK'
soup.select("td.subscriber_cnt")[0].string
'9610만'
soup.select("td.view_cnt")[0].string
'382억6552만'
soup.select("td.video_cnt")[0].string
'605개'
soup.select("td.hit>strong")[0].string
'48,431'
# 10페이지까지 데이터 수집
result_dict = {"cate" : [],
"title" : [],
"subscriber" : [],
"view" : [],
"video" : [],
"hit" : []}
base_url = "https://youtube-rank.com/board/bbs/board.php?bo_table=youtube&page="
for page_num in range(1, 11):
page = urlopen(base_url + str(page_num))
soup = BeautifulSoup(page, "lxml")
result_dict["cate"] += soup.select("p.category")
result_dict["title"] += soup.select("td.subject > a")
result_dict["subscriber"] += soup.select("td.subscriber_cnt")
result_dict["view"] += soup.select("td.view_cnt")
result_dict["video"] += soup.select("td.video_cnt")
result_dict["hit"] += soup.select("td.hit>strong")
print(len(result_dict["cate"]))
print(len(result_dict["title"]))
print(len(result_dict["subscriber"]))
print(len(result_dict["view"]))
print(len(result_dict["video"]))
print(len(result_dict["hit"]))
1000
1000
1000
1000
1000
1000
result_dict["cate"] = [i.string.strip() for i in result_dict["cate"]]
result_dict["title"] = [i.string.strip() for i in result_dict["title"]]
result_dict["subscriber"] = [i.string.strip() for i in result_dict["subscriber"]]
result_dict["view"] = [i.string.strip() for i in result_dict["view"]]
result_dict["video"] = [i.string.strip() for i in result_dict["video"]]
result_dict["hit"] = [i.string.strip() for i in result_dict["hit"]]
df = pd.DataFrame(result_dict)
df.head()

# 데이터프레임을 엑셀로 저장
df.to_excel("youtube_rank.xlsx", index = False)
유튜브 랭킹 데이터 분석
df.head()

- subscriber 는 모든 데이터가 ~만 으로 조합된 문자열 값
- 만 -> 0000으로 치환하여 int타입 변환
df["subscriber"] = df["subscriber"].str.replace("만", "0000").astype(int)
df.head()

df.shape
(1000, 6)
df.dtypes
cate object
title object
subscriber int32
view object
video object
hit object
dtype: object
카테고리별 구독자 수, 채널 수 분석
# 카테고리별 구독자수, 채널 수
casub = df.groupby("cate")["subscriber"].agg(["sum", "count"])
casub

# 데이터프레임 내림차순 정렬
casub = casub.sort_values("sum", ascending = False)
casub.head()

# 구독자 수 파이차트 시각화
plt.figure()
plt.pie(casub["sum"], labels = casub.index, autopct = "%.1f%%")
plt.title("카테고리별 구독자 수")
plt.show()

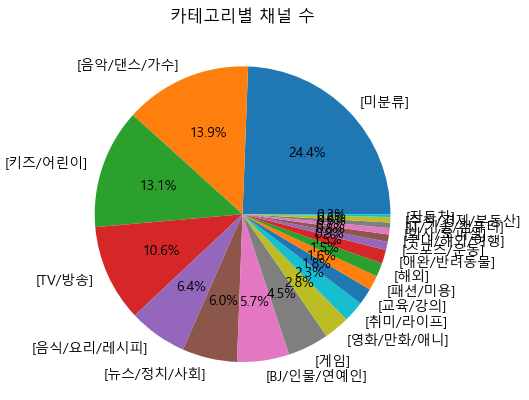
# 카테고리별 채널 수
casub = casub.sort_values("count", ascending = False)
plt.figure()
plt.pie(casub["count"], labels = casub.index, autopct = "%.1f%%")
plt.title("카테고리별 채널 수")
plt.show()
728x90
'07_Data_Analysis' 카테고리의 다른 글
| 19_Wordcloud, Polium_제주도 맛집 데이터 (6) | 2025.03.20 |
|---|---|
| 18_외국인 관광객 데이터 분석 (0) | 2025.03.20 |
| 16_기온 데이터 분석 (0) | 2025.03.19 |
| 15_카이제곱 검정(교차분석) (0) | 2025.03.19 |
| 14_ANOVA(ANalysis Of VAriance) (2) | 2025.03.19 |