728x90
데이터 전처리
- 데이터 분석의 정확도는 분석 데이터의 품질에 의해 좌우됨
- 데이터 품질을 높이기 위해 누락 데이터, 중복 데이터 등의 오류를 수정하고 분석 목적에 맞게 변형하는 과정이 필요
- 수집한 데이터를 분석에 적합하도록 만드는 과정을 전처리라고 함
01. 누락 데이터 처리
- 데이터프레임에는 여러가지 이유로 원소 데이터 값이 누락되는 경우가 종종 있음
- 데이터를 파일로 입력할 때 빠뜨리거나 파일 형식을 변환하는 과정에서 데이터가 소실되는 것이 주요 원인
- 일반적으로 누락 데이터를 NaN(Not a Number)으로 표시
- 머신러닝 분석 모형에 데이터를 입력하기 전에 누락 데이터를 제거하거나 다른 적절한 값으로 대체하는 과정이 필요
- 누락 데이터가 많아지면 데이터의 품질이 떨어지고, 머신러닝 분석 알고리즘을 왜곡하는 현상이 발생
- 누락 데이터를 찾는 메소드
- 누락 데이터를 True로 반환, 유효한 데이터를 False로 반환
- isnull()
- isna() ※ 두 값의 차이는 없으므로 둘중 하나를 사용
- 누락 데이터를 False로 반환
- notnull()
- notna() ※ 두 값의 차이는 없으므로 둘중 하나를 사용
- 누락 데이터를 True로 반환, 유효한 데이터를 False로 반환
import pandas as pd
import seaborn as sns
import numpy as np
df = sns.load_dataset("titanic")
df.head()

df.shape
(891, 15)
df.dtypes
survived int64
pclass int64
sex object
age float64
sibsp int64
parch int64
fare float64
embarked object
class category
who object
adult_male bool
deck category
embark_town object
alive object
alone bool
dtype: object
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KB
# deck 열의 NaN 개수 계산하기
# dropna = False를 사용하지 않으면 NaN값을 제외하고 유효한 데이터의 개수만을 구함
nan_deck = df["deck"].value_counts(dropna = False)
nan_deck
deck
NaN 688
C 59
B 47
D 33
E 32
A 15
F 13
G 4
Name: count, dtype: int64
# isnull() 메서드로 누락 데이터 찾기
df.head().isnull()
# notnull() 메서드로 누락 데이터 찾기
df.head().notnull()

# isnull() 메서드로 누락 데이터 개수 구하기
df.isnull().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
누락 데이터 제거
# NaN 값이 500개 이상인 열을 모두 삭제
df_thresh = df.dropna(axis = 1, thresh = 500)
df_thresh.head() #deck가500개 이상이므로 빠짐
# age열에 나이 데이터가 없는 모든 행을 삭제
df_age = df.dropna(subset = ["age"], how = "any", axis = 0)
df_age.shape[0]
714- dropna()
- subset : 특정 열에 NaN 값이 있는 모든 행
- how = "any" : NaN 값이 하나라도 존재하면 삭제
- how = "all" : 모든 데이터가 NaN 값일 경우에만 삭제
- 기본값은 any
# age열, deck열 양쪽 모두 데이터가 없는 행 삭제
df_age_deck = df.dropna(subset = ["age", "deck"], how = "all", axis = 0)
df_age_deck.shape[0]
733
누락 데이터 치환
- 누락 데이터를 무작정 삭제한다면 데이터가 지나치게 줄어들 수 있음
- 분석 정확도는 데이터의 품질 외에도 제공되는 데이터의 양에 상당한 영향을 받음
- 데이터 중에 일부 누락되어 있더라도 나머지 데이터를 최대한 활용해야함
- 누락 데이터를 대체할 값
- 데이터의 분포와 특성을 잘 나타낼 수 있는 값
- 평균값
- 최빈값 등
- fillna() 메소드로 처리
- 새로운 객체를 반환
- ffill() / bfill() 메소드
- 데이터셋에서 서로 이웃하고 있는 데이터끼리는 유사성을 가질 가능성이 높음
- 앞이나 뒤에서 이웃하고 있는 값으로 치환하는 경우도 있음
- ffill() : NaN이 있는 행의 직전 행에 있는 값으로 치환
- bfill() : NaN이 있는 행의 바로 다음 행에 있는 값으로 치환
- 데이터셋에서 서로 이웃하고 있는 데이터끼리는 유사성을 가질 가능성이 높음
- 데이터의 분포와 특성을 잘 나타낼 수 있는 값
df["age"].head(10)
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 NaN
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64# age 열의 NaN 값을 다른 나이 데이터의 평균으로 변경하기
mean_age = df["age"].mean() # age 열의 평균 계산
mean_age
29.69911764705882
df["age"].fillna(mean_age)
0 22.000000
1 38.000000
2 26.000000
3 35.000000
4 35.000000
...
886 27.000000
887 19.000000
888 29.699118
889 26.000000
890 32.000000
Name: age, Length: 891, dtype: float64
df["age"].head(10)
# 비파괴적이므로 변수에 할당을 해줘야 결괏값이 변한다
df["age"] = df["age"].fillna(mean_age)
df["age"].head(10)
0 22.000000
1 38.000000
2 26.000000
3 35.000000
4 35.000000
5 29.699118
6 54.000000
7 2.000000
8 27.000000
9 14.000000
Name: age, dtype: float64
# embark_town 열의 NaN 데이터 출력
df["embark_town"][825:830]
825 Queenstown
826 Southampton
827 Cherbourg
828 Queenstown
829 NaN
Name: embark_town, dtype: object
# embark_town 열의 NaN 값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
most_freq = df["embark_town"].value_counts().idxmax() # 최대값의 인덱스 idxmax()
most_freq
'Southampton'
df["embark_town"] = df["embark_town"].fillna(most_freq)
df["embark_town"][825:830]
825 Queenstown
826 Southampton
827 Cherbourg
828 Queenstown
829 Southampton
Name: embark_town, dtype: object
df = sns.load_dataset("titanic")
df["embark_town"][825:830]
825 Queenstown
826 Southampton
827 Cherbourg
828 Queenstown
829 NaN
Name: embark_town, dtype: object
# embark_town 열의 NaN 값을 바로 앞에 있는 828행의 값으로 변경하기
df["embark_town"] = df["embark_town"].ffill()
df["embark_town"][825:830]
825 Queenstown
826 Southampton
827 Cherbourg
828 Queenstown
829 Queenstown
Name: embark_town, dtype: object
누락 데이터가 NaN으로 표시되지 않는 경우
- 누락 데이터가 NaN이 아닌 0이나 "-", "?"같은 값으로 입력되는 경우도 있음
- 데이터 객체의 replace() 메소드를 활용하여 np.nan 으로 결측처리 해주어야함
02. 중복 데이터 처리
- 데이터프레임에서 각 행은 분석 대상이 갖고 있는 모든 속성에 대한 관측값을 뜻함
- 하나의 데이터셋에서 동일한 관측값이 중복되는 경우 분석 결과를 왜곡할 수 있기 때문에 삭제해야함
중복 데이터 확인
- duplicated()
- 행의 레코드가 중복되는지 여부를 확인
- 전에 나온 행들과 비교하여 중복되는 행이면 True를 반환하고 처음 나오는 행은 False를 반환
- 데이터프레임에 duplicated() 메소드를 적용하면 각 행의 중복여부를 나타내는 boolean시리즈를 반환
# 중복 데이터를 갖는 데이터프레임
df = pd.DataFrame({"c0" : ["a", "a", "b", "a", "b"],
"c1" : [1, 1, 1, 2, 2],
"c2" : [1, 1, 2, 2, 2]})
df.head()

# 데이터프레임 전체 행 데이터 중에서 중복값 찾기
df_dup = df.duplicated()
df_dup
0 False
1 True
2 False
3 False
4 False
dtype: bool# 특정 열 데이터에서 중복값 찾기
col_dup = df["c1"].duplicated()
col_dup
0 False
1 True
2 True
3 False
4 True
Name: c1, dtype: bool
중복 데이터 제거
- drop_duplicates()
- 중복되는 행을 제거하고 고유한 관측값을 가진 행들만 유지
- subset 옵션에 열 이름의 리스트를 전달할 수 있음
- 중복 여부를 판별할 때, subset 옵션에 해당하는 열을 기준으로 판단
df

# 데이터프레임에서 중복 행 제거
df2 = df.drop_duplicates()
df2

# c1, c2 열을 기준으로 중복 행을 제거
df3 = df.drop_duplicates(subset = ["c1", "c2"])
df3

03. 데이터 표준화
- 실무에서 접하는 데이터들은 다양한 곳에서 수집되어 여러가지 원인에 의해 다양한 형태로 표현될 수 있음
- 단위 선택
- 대소문자 구분
- 약칭 활용 등
- 이처럼 동일한 대상을 표현하는 방법에 차이가 있으면 분석의 정확도는 현저하게 낮아짐
- 데이터 형식을 일관성 있게 표준화 하는 작업이 필요
- 데이터 표준화
- 데이터 형식을 일관성 있게 표준화 하는 작업이 필요
단위 환산
- 같은 데이터셋 안에는 측정 단위를 동일하게 맞춰 줘야 함
- 특히 외국 데이터를 가져오면 국내에서 사용하지 않는 도량형 단위를 사용하는 경우가 많아서 주의가 필요
- 마일, 야드, 온스 등
- 특히 외국 데이터를 가져오면 국내에서 사용하지 않는 도량형 단위를 사용하는 경우가 많아서 주의가 필요
df = pd.read_csv("./data/auto-mpg.csv", header = None)
df.columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model_year", "origin", "name"]
df.head()

# mpg(mile per gallon)를 kpl(kilometer per lister)로 변환 (mpg_to_kpl = 0.425)
mpg_to_kpl = 1.60934 / 3.78541
mpg_to_kpl
0.42514285110463595
# mpg 열에 0.425를 곱한 결과를 새로운 열(kpl)에 추가
df["kpl"] = df["mpg"] * mpg_to_kpl
df.head()

# kpl 열을 소수점 아래 둘째 자리까지 반올림
df["kpl"] = df["kpl"].round(2)
df.head()
자료형 변환
- 숫자가 문자열로 저장된 경우에는 숫자형으로 변환해야함
- dtype 속성을 사용하여 데이터프레임을 구성하는 각 열의 자료형을 확인해야함
df.dtypes
mpg float64
cylinders int64
displacement float64
horsepower object
weight float64
acceleration float64
model_year int64
origin int64
name object
kpl float64
dtype: object
# horsepower 열의 고유값 확인
df["horsepower"].unique()
array(['130.0', '165.0', '150.0', '140.0', '198.0', '220.0', '215.0',
'225.0', '190.0', '170.0', '160.0', '95.00', '97.00', '85.00',
'88.00', '46.00', '87.00', '90.00', '113.0', '200.0', '210.0',
'193.0', nan, '100.0', '105.0', '175.0', '153.0', '180.0', '110.0',
'72.00', '86.00', '70.00', '76.00', '65.00', '69.00', '60.00',
'80.00', '54.00', '208.0', '155.0', '112.0', '92.00', '145.0',
'137.0', '158.0', '167.0', '94.00', '107.0', '230.0', '49.00',
'75.00', '91.00', '122.0', '67.00', '83.00', '78.00', '52.00',
'61.00', '93.00', '148.0', '129.0', '96.00', '71.00', '98.00',
'115.0', '53.00', '81.00', '79.00', '120.0', '152.0', '102.0',
'108.0', '68.00', '58.00', '149.0', '89.00', '63.00', '48.00',
'66.00', '139.0', '103.0', '125.0', '133.0', '138.0', '135.0',
'142.0', '77.00', '62.00', '132.0', '84.00', '64.00', '74.00',
'116.0', '82.00'], dtype=object)# 누락 데이터("?") 삭제
df["horsepower"] = df["horsepower"].replace("?", np.nan) # '?'를 np.nan으로 변경
df = df.dropna(subset = ["horsepower"], axis = 0) # 누락데이터 행을 삭제
df["horsepower"] = df["horsepower"].astype("float") # 문자열을 실수형으로 변환
df["horsepower"].dtypes
dtype('float64')
# origin 열의 고유값 확인
df["origin"].unique()
array([1, 3, 2], dtype=int64)
# 정수형 데이터를 문자형 데이터로 변환
df["origin"] = df["origin"].replace({1 : "USA", 2: "EU", 3 : "JAPAN"})
df["origin"].unique()
array(['USA', 'JAPAN', 'EU'], dtype=object)df["origin"].dtypes # dtype('O') 의 O는 Object를 의미
dtype('O')
04. 범주형 데이터 처리
구간 분할
- 데이터 분석 알고리즘에 따라서는 연속 데이터를 일정한 구간으로 나눠서 분석하는 것이 효율적인 경우가 있음
- 가격, 비용, 효율 등 연속적인 값을 일정한 수준이나 정도를 나타내는 이산값으로 나타내어 구간별 차이를 드러냄
- 연속 변수를 일정 구간으로 나누고 각 구간을 범주형 이산 변수로 변환하는 과정을 구간 분할(binning)이라고 함
df.head()
# horsepower를 3개의 구간으로 나누는 경계 값의 리스트 구하기
count, bin_dividers = np.histogram(df["horsepower"], bins = 3)
bin_dividers
array([ 46. , 107.33333333, 168.66666667, 230. ])
count
array([257, 103, 32], dtype=int64)
# 3개의 구간에 이름 지정
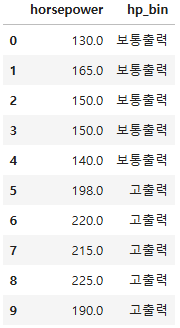
bin_names = ["저출력", "보통출력", "고출력"]
# 각 데이터를 3개의 구간에 할당
df["hp_bin"] = pd.cut(x = df["horsepower"], # 데이터 배열
bins = bin_dividers, # 경계값 리스트
labels = bin_names, # bin 이름
include_lowest = True) # 첫 경계값 포함
df[["horsepower", "hp_bin"]].head(10)
더미 변수
- 범주형 데이터를 머신러닝 알고리즘에 바로 사용할 수 없는 경우에는 컴퓨터가 인식 가능한 값으로 변환해야 함
- 이 때 숫자 0 또는 1로 표현되는 더미 변수(dummy variable)를 사용
- 0과 1은 수의 크고 작음이 아니라 어떤 특성이 있는지 없는지 여부만을 표시
- 해당 특성이 존재하면 1, 존재하지 않으면 0
- 범주형 데이터를 컴퓨터가 인식할 수 있도록 0과 1로만 구성되는 벡터로 변환하는 것을 원핫인코딩 이라고 부름
# hp_bin 열의 범주형 데이터를 더미 변수로 변환
# horsepower_dummies = pd.get_dummies(df["hp_bin"], dtype = float) 결과를 숫자로 나타내고 싶은 경우
horsepower_dummies = pd.get_dummies(df["hp_bin"])
horsepower_dummies.head(10)
05. 정규화
- 각 변수의 상대적 크기 차이 때문에 머신러닝 분석의 결과가 달라질 수 있음
- 예) 0 ~ 1000 범위의 값을 갖는 변수와 0 ~ 1 범위의 값을 갖는 변수 중 상대적으로 큰 숫자 값을 갖는 변수의 영향이 더 커짐
- 숫자 데이터의 상대적인 크기 차이를 제거할 필요가 있음
- 각 열에 속하는 데이터값을 동일한 기준으로 나눈 비율로 나타내는 것을 정규화(normalization)라고 함
- 일반적으로 데이터의 범위는 0 ~ 1 또는 -1 ~ 1 로 정규화
- 가장 간단한 정규화 방법은 데이터를 해당 열의 최댓값으로 나누는 방법 (※ 최댓값으로 나누면 가장 큰 값이 1이 됨)
df["horsepower"].describe()
count 392.000000
mean 104.469388
std 38.491160
min 46.000000
25% 75.000000
50% 93.500000
75% 126.000000
max 230.000000
Name: horsepower, dtype: float64
# horsepower열의 절대값의 최댓값으로 모든 데이터를 나눠서 저장
df["horsepower"] = df["horsepower"] / abs(df["horsepower"]).max()
df["horsepower"].head()
0 0.565217
1 0.717391
2 0.652174
3 0.652174
4 0.608696
Name: horsepower, dtype: float64
df["horsepower"].describe()
count 392.000000
mean 0.454215
std 0.167353
min 0.200000
25% 0.326087
50% 0.406522
75% 0.547826
max 1.000000
Name: horsepower, dtype: float64
- 각 열의 데이터 중에서 최댓값과 최솟값을 뺀 값으로 나누는 방법도 있음
x-min(x) / max(x) - min(x)
※ 최솟값은 0 최댓값은 1
df = pd.read_csv("./data/auto-mpg.csv", header = None)
df.columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model_year", "origin", "name"]
# 누락 데이터("?") 삭제
df["horsepower"] = df["horsepower"].replace("?", np.nan) # '?'를 np.nan으로 변경
df = df.dropna(subset = ["horsepower"], axis = 0) # 누락데이터 행을 삭제
df["horsepower"] = df["horsepower"].astype("float") # 문자열을 실수형으로 변환
min_x = df["horsepower"] - df["horsepower"].min()
min_max = df["horsepower"].max() - df["horsepower"].min()
df["horsepower"] = min_x / min_max
df["horsepower"].head()
0 0.456522
1 0.646739
2 0.565217
3 0.565217
4 0.510870
Name: horsepower, dtype: float64
df["horsepower"].describe()
count 392.000000
mean 0.317768
std 0.209191
min 0.000000
25% 0.157609
50% 0.258152
75% 0.434783
max 1.000000
Name: horsepower, dtype: float64
05. 시계열 데이터
- 시계열 데이터란 일정 시간 간격으로 배치된 데이터들의 수열을 의미
- 시계열 데이터를 데이터프레임의 행 인덱스로 사용하면 시간으로 기록된 데이터를 분석하는 것이 편리함
다른 자료형을 시계열 객체로 변환
- to_datetime()
df = pd.read_csv("./data/stock-data.csv")
df.head()

df.shape
(20, 6)
df.dtypes
Date object
Close int64
Start int64
High int64
Low int64
Volume int64
dtype: object
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 20 non-null object
1 Close 20 non-null int64
2 Start 20 non-null int64
3 High 20 non-null int64
4 Low 20 non-null int64
5 Volume 20 non-null int64
dtypes: int64(5), object(1)
memory usage: 1.1+ KB
# 파이썬 포맷코드
https://docs.python.org/ko/3.8/library/datetime.html#strftime-and-strptime-behavior
df["new_date"] = pd.to_datetime(df["Date"], format = "%Y-%m-%d") # format은 입력값의 형식
df.head()

df.dtypes
Date object
Close int64
Start int64
High int64
Low int64
Volume int64
new_date datetime64[ns]
dtype: object
# dt 속성을 이용하여 new_date 열의 연월일 정보를 구분
df["year"] = df["new_date"].dt.year
df["month"] = df["new_date"].dt.month
df["day"] = df["new_date"].dt.day
df.head()

'05_Pandas' 카테고리의 다른 글
| 05_데이터프레임 응용 (0) | 2025.03.06 |
|---|---|
| 04-1_연습문제_iris (0) | 2025.03.06 |
| 03-1_연습문제_occupation (0) | 2025.03.05 |
| 03_데이터 탐색 (1) | 2025.03.05 |
| 02_Pandas_데이터 입출력 (0) | 2025.03.05 |