728x90
데이터 탐색
01. 데이터 프레임의 구조
- auto mpg 데이터셋
- 출처 : UCI 머신러닝 저장소(https://archive.ics.uci.edu/)
- 속성
- mpg
- 연비
- 연속형
- cylinders
- 실린더 수
- 이산형
- displacement
- 배기량
- 연속형
- horsepower
- 출력
- 연속형
- weight
- 차중
- 연속형
- acceleration
- 가속능력
- 연속형
- model_year
- 출시년도
- 이산형
- origin
- 제조국
- 이산형(1(usa), 2(eu), 3(jpn))
- name
- 모델명
- 문자열
- mpg
02. 데이터 내용 파악
- head()
- 데이터프레임의 앞부분 일부 내용 출력
- 데이터셋의 내용과 구조를 개략적으로 살펴볼 수 있기 때문에 분석 방향을 정하는 데 필요한 정보를 얻을 수 있음
- 데이터프레임이 너무 커서 한 화면에 출력하기 어려울 때 사용하기도 함
- 인자로 정수 n을 전달하면 처음 n개 행을 출력
- 기본값: 5
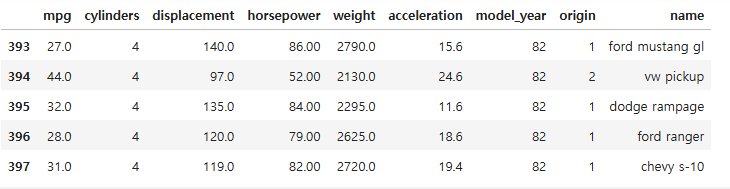
- tail()
- 데이터프레임의 마지막 부분 일부 출력
import pandas as pd
df = pd.read_csv("./data/auto-mpg.csv", header = None)
# 열 이름을 지정
df.columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model_year", "origin", "name"]
df.head(3)

# 마지막 5개 행
df.tail()
03. 데이터 요약 정보 확인
데이터프레임의 크기(행, 열)
- shape 속성
- 행과 열의 개수를 튜플 형태로 반환
# df의 모양과 크기 확인
df.shape
(398, 9)
데이터프레임의 기본 정보
- info()
- 데이터프레임의 기본 정보를 출력
- 클래스 유형
- 행 인덱스 구성
- 열 이름의 종류와 개수
- 각 열의 자료형과 개수
- 메모리 할당량
- 데이터프레임의 기본 정보를 출력
# df의 내용 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 398 non-null object
4 weight 398 non-null float64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null int64
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
04. 판다스 자료형
- 판다스는 numpy를 기반으로 만들어졌음
- numpy에서 사용하는 자료형을 기본적으로 사용할 수 있음
- 정수형 / 실수형 데이터
- 판다스 : int64 / float64
- 파이썬 : int / float
- 문자열 데이터
- 판다스 : object
- 파이썬 : string
- 시간 데이터
- 판다스 : datetime64, timedelta64
- 파이썬 : datetime(라이브러리 활용)
# df의 자료형 확인
df.dtypes
mpg float64
cylinders int64
displacement float64
horsepower object
weight float64
acceleration float64
model_year int64
origin int64
name object
dtype: object
# 특정 시리즈의 자료형 확인
df["mpg"].dtypes
dtype('float64')
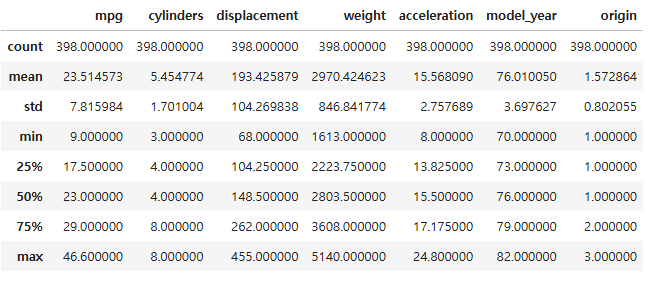
05. 데이터프레임의 기술 통계 정보 요약
- describe()
- 수치형 데이터를 갖는 열에 대한 주요 기술 통계 정보를 요약하여 출력
- 평균
- 표준편차
- 최댓값
- 최솟값
- 중앙값
- 수치형 데이터가 아닌 열에 대한 정보를 포함하고 싶으면 include = "all" 옵션을 추가
- 수치형 데이터를 갖는 열에 대한 주요 기술 통계 정보를 요약하여 출력
# df의 기술통계 정보 확인
df.describe()
df.describe(include = "all")

* top: 최빈값
*freq: 최빈값의 빈도
06. 데이터 개수 확인
각 열의 데이터 개수
- info() 메소드는 각 열의 데이터 개수 정보를 출력하지만 반환 값이 없어 재사용이 어려움
- count()
- 데이터프레임의 각 열이 가지고 있는 데이터 개수를 시리즈 객체로 반환
- 유효한 값의 개수만을 계산
# df 각 열이 가지고 있는 원소 개수 확인
df.count()
mpg 398
cylinders 398
displacement 398
horsepower 398
weight 398
acceleration 398
model_year 398
origin 398
name 398
dtype: int64각 열의 고유값 개수
- value_counts()
- 시리즈 객체의 고유값의 종류와 개수를 확인
- 고유값이 행 인덱스, 고유값의 개수가 데이터 값이 되는 시리즈 객체
- dropna = True 옵션
- 데이터 값 중에서 NaN을 제외하고 개수를 계산
- 기본값
- dropna = False
- NaN이 포함
# df의 특정 열이 가지고 있는 고유값 확인
df["origin"].value_counts()
origin
1 249
3 79
2 70
Name: count, dtype: int64
# 특정 열이 가지고 있는 고유값의 비율을 확인
df["origin"].value_counts(normalize = True)
origin
1 0.625628
3 0.198492
2 0.175879
Name: proportion, dtype: float64
07. 통계 함수 적용
평균
- mean()
- 산술 데이터를 갖는 모든 열의 평균값을 각각 계산하여 시리즈 객체로 반환
- 특정 열을 선택하여 평균값을 계산하는 것도 가능
df.mean()
df["열이름"].mean()
df.head()

df.mean(numeric_only = True) # 평균
mpg 23.514573
cylinders 5.454774
displacement 193.425879
weight 2970.424623
acceleration 15.568090
model_year 76.010050
origin 1.572864
dtype: float64
df["mpg"].mean()
23.514572864321607
df[["mpg", "weight"]].mean()
mpg 23.514573
weight 2970.424623
dtype: float64
중앙값
- median()
df.median(numeric_only = True) # 중앙값
mpg 23.0
cylinders 4.0
displacement 148.5
weight 2803.5
acceleration 15.5
model_year 76.0
origin 1.0
dtype: float64
df["mpg"].median()
23.0
최댓값
- max()
- 문자열 데이터를 가진 열에 대해서는 문자열을 ASCII 숫자로 변환하여 크고 작음을 비교
df.max() # horsepower는 ?라 문자열로 인식되었음
mpg 46.6
cylinders 8
displacement 455.0
horsepower ?
weight 5140.0
acceleration 24.8
model_year 82
origin 3
name vw rabbit custom
dtype: object
df["mpg"].max()
46.6
최솟값
- min()
df.min()
mpg 9.0
cylinders 3
displacement 68.0
horsepower 100.0
weight 1613.0
acceleration 8.0
model_year 70
origin 1
name amc ambassador brougham
dtype: objectdf["mpg"].min()
9.0
- horsepower 열은 "?" 문자가 섞여있어 다른 숫자값도 모두 문자열로 인식되었음
- 문자를 제거하거나 적절한 숫자로 바꾸고 숫자형 데이터로 변환해야함
표준편차
- std()
df.std(numeric_only = True)
mpg 7.815984
cylinders 1.701004
displacement 104.269838
weight 846.841774
acceleration 2.757689
model_year 3.697627
origin 0.802055
dtype: float64df["mpg"].std()
7.815984312565782
상관계수
- corr()
- 두 열 간의 상관계수를 계산
- 산술 데이터를 갖는 모든 열에 대하여 2개씩 짝을 짓고 각각의 경우에 대하여 상관계수를 계산
- 문자열을 가진 열은 계산이 불가능하기 때문에 포함하지 않음
df.corr(numeric_only = True)
# 상관계수: -1 ~ 1사이의 값으로 절댓값이 높을 수록 상관관계가 높음 0.3이하 관계없다.
절댓값이 0.7이상 일 경우 관계 있다고 볼 수 있음

df[["mpg", "weight"]].corr()

08. 판다스(pandas) 내장 그래프 도구
- 그래프를 이용한 시각화는 데이터의 분포와 패턴을 파악하는 데 큰 도움이 됨
- 판다스는 matplotlib 라이브러리의 기능을 일부 내장하고 있음
- 별도의 import없이 간단한 그래프를 그리는 것이 가능
- 그래프의 종류
- line : 선 그래프
- bar : 수직 막대 그래프
- barh : 수평 막대 그래프
- his : 히스토그램
- box : 박스플롯
- kde : 커널 밀도 그래프
- area : 면적 그래프
- pie : 파이 그래프
- scatter : 산점도 그래프
- hexbin : 고밀도 산점도 그래프
선 그래프
- plot() 메소드를 적용할 때 다른 옵션을 추가하지 않으면 기본적으로 선 그래프를 그림

df = pd.read_excel("./data/남북한발전전력량.xlsx")
df.head(6)

df_ns = df.iloc[[0, 5], 2:] # 남한, 북한 발전량 합계 데이터만 추출
df_ns.head()

# 행 인덱스 변경
df_ns.index = ["South", "North"]
df_ns.head()

# 선그래프 그리기
df_ns.plot()

- 데이터프레임의 plot() 메소드를 사용하면 행 인덱스를 x축으로 사용하기 때문에 south, north 값이 x축으로 전달되었음
- 시간의 흐름에 따른 연도별 발전량 변화 추이를 보기 위해서는 연도값이 x축에 표시되어야 함
- 연도값을 x축으로 바꾸기 위해서 행렬을 전치
- 시간의 흐름에 따른 연도별 발전량 변화 추이를 보기 위해서는 연도값이 x축에 표시되어야 함
# 행, 열 전치하여 다시 그리기
tdf_ns = df_ns.T
tdf_ns.head()

tdf_ns.plot()

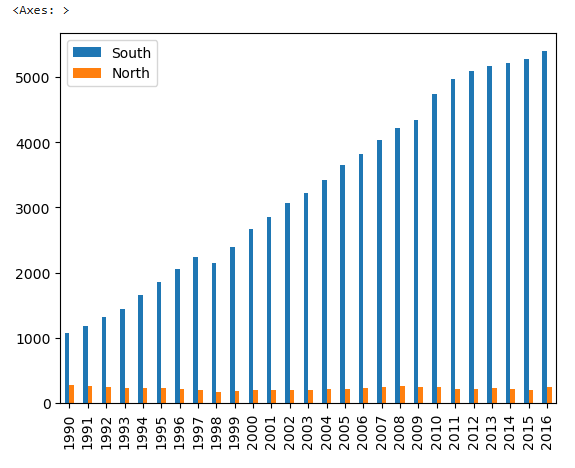
- 남한의 발전량은 계속 증가하였고 북한은 큰 변화가 없음
막대 그래프
- plot() 메소드의 kind 옵션에서 그래프 종류를 지정
- 막대그래프는 kind = "bar" 옵션을 추가
tdf_ns.plot(kind = "bar")
히스토그램
- kind = "hist"
- 히스토그램의 x축은 발전량을 일정한 간격을 갖는 여러 구간으로 나눈 것
- y축은 연간 발전량이 x축에서 나눈 발전량 구간에 속하는 연도의 수를 빈도로 나타낸 것
tdf_ns.dtypes
South object
North object
dtype: object
tdf_ns = tdf_ns.astype("int64") # 수치형으로 변경
tdf_ns.dtypes
South int64
North int64
dtype: object
tdf_ns.plot(kind = "hist")

- 북한은 27년간 약 800 미만의 발전량을 기록
산점도
- kind = "scatter"
df = pd.read_csv("./data/auto-mpg.csv", header = None)
df.columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model_year", "origin", "name"]
df.head()

# 2개의 열을 선택하여 산점도 그리기
df.plot(x = "weight", y = "mpg", kind = "scatter")

- weight가 클수록 mpg는 낮아지는 경향을 보임
- 차량의 무게와 연비는 음의 상관관계를 갖는다
박스 플롯
- 특정 변수의 데이터 분포와 분산 정도에 대한 정보를 제공
- kind = "box"
# 열을 선택하여 박스 플롯 그리기
df[["mpg", "cylinders"]].plot(kind = "box")

# 메모: 박스플롯
ㅇ : 이상치
- : 중앙값
최댓값: Q3 + 1.5IQR
최소값: Q1 - 1.5IQR
- mpg
- 넓은 범위로 분포되어 있고 이상값도 확인됨
- cylinders
- 10미만의 좁은 범위에 몰려있음
728x90
'05_Pandas' 카테고리의 다른 글
| 04_데이터 전처리 (1) | 2025.03.06 |
|---|---|
| 03-1_연습문제_occupation (0) | 2025.03.05 |
| 02_Pandas_데이터 입출력 (0) | 2025.03.05 |
| 01-1_연습문제_포켓몬 (0) | 2025.03.04 |
| 01_판다스(Pandas) 자료구조 (0) | 2025.03.04 |