728x90
데이터프레임 응용
01. 함수 매핑
- 시리즈 또는 데이터프레임의 개별 원소를 특정 함수에 일대일 대응시키는 과정
- 사용자가 직접 만든 함수를 적용할 수 있기 때문에 판다스 기본 함수로 처리하기 어려운 복잡한 연산을 적용하는 것이 가능
개별 원소에 함수 매핑
시리즈 원소에 함수 매핑
- 시리즈에 map() 을 적용하면 인자로 전달받는 매핑 함수에 시리즈의 모든 원소를 하나씩 입력하고 리턴값을 받음
- 시리즈 원소의 개수만큼 리턴값을 받아서 같은 크기의 시리즈 객체로 변환
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset("titanic")
df = titanic.loc[:, ["age", "fare"]]
df["ten"] = 10
df.head()

# 10을 더하는 함수
def add_10(n):
return n + 10
df["age"].map(add_10)
0 32.0
1 48.0
2 36.0
3 45.0
4 45.0
...
886 37.0
887 29.0
888 NaN
889 36.0
890 42.0
Name: age, Length: 891, dtype: float64df["age"].map(lambda x: x + 10)
0 32.0
1 48.0
2 36.0
3 45.0
4 45.0
...
886 37.0
887 29.0
888 NaN
889 36.0
890 42.0
Name: age, Length: 891, dtype: float64
데이터프레임 원소에 함수 매핑
df.head()
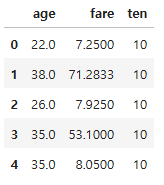
df.map(lambda x : x + 10)
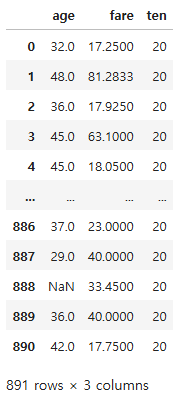
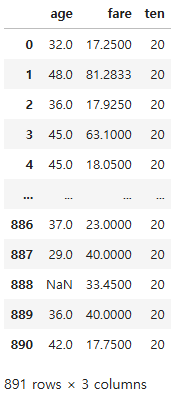
df.map(add_10)
데이터프레임 객체에 함수 매핑
- apply()
df.apply(lambda x: x["age"] + x["fare"], axis = 1) # axis: 진행방향
0 29.2500
1 109.2833
2 33.9250
3 88.1000
4 43.0500
...
886 40.0000
887 49.0000
888 NaN
889 56.0000
890 39.7500
Length: 891, dtype: float64
02. 열 분리
- 하나의 열이 여러 가지 정보를 담고 있으면 정보를 분리해야함
- 예) 어떤 열에 연월일 정보가 있을 때 연, 월, 일을 구분하여 3개의 열로 분리
df = pd.read_excel("./data/주가데이터.xlsx")
df.head()
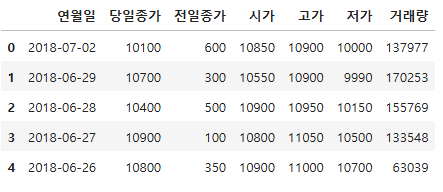
df.shape
(20, 7)
df.dtypes
연월일 datetime64[ns]
당일종가 int64
전일종가 int64
시가 int64
고가 int64
저가 int64
거래량 int64
dtype: object
# df["연월일"].dt.year
df["연월일"] = df["연월일"].astype("str") # 문자열 메소드 사용을 위해 자료형 변경
df.dtypes
연월일 object
당일종가 int64
전일종가 int64
시가 int64
고가 int64
저가 int64
거래량 int64
dtype: object
dates = df["연월일"].str.split("-") # 문자열을 split() 메소드로 분리
dates.head()
0 [2018, 07, 02]
1 [2018, 06, 29]
2 [2018, 06, 28]
3 [2018, 06, 27]
4 [2018, 06, 26]
Name: 연월일, dtype: object
"2018-07-02".split("-")
['2018', '07', '02']# 시리즈 안에 있는 데이터 값이 문자열이므로, 이하는 에러발생
df["연월일"].split("-")
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[57], line 1
----> 1 df["연월일"].split("-")
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\core\generic.py:6299, in NDFrame.__getattr__(self, name)
6292 if (
6293 name not in self._internal_names_set
6294 and name not in self._metadata
6295 and name not in self._accessors
6296 and self._info_axis._can_hold_identifiers_and_holds_name(name)
6297 ):
6298 return self[name]
-> 6299 return object.__getattribute__(self, name)
AttributeError: 'Series' object has no attribute 'split'
df["연"] = dates.str.get(0) # dates 변수의 원소 리스트의 0번째 인덱스 값
df["월"] = dates.str.get(1)
df["일"] = dates.str.get(2)
df.head()

# dates.str.get(0)
dates.str[0]
0 2018
1 2018
2 2018
3 2018
4 2018
5 2018
6 2018
7 2018
8 2018
9 2018
10 2018
11 2018
12 2018
13 2018
14 2018
15 2018
16 2018
17 2018
18 2018
19 2018
Name: 연월일, dtype: object
dates.str[1:]
0 [07, 02]
1 [06, 29]
2 [06, 28]
3 [06, 27]
4 [06, 26]
5 [06, 25]
6 [06, 22]
7 [06, 21]
8 [06, 20]
9 [06, 19]
10 [06, 18]
11 [06, 15]
12 [06, 14]
13 [06, 12]
14 [06, 11]
15 [06, 08]
16 [06, 07]
17 [06, 05]
18 [06, 04]
19 [06, 01]
Name: 연월일, dtype: object
03. 필터링
- 시리즈 또는 데이터프레임의 데이터 중에서 특정 조건식을 만족하는 원소만 따로 추출
불리언 인덱싱
- 시리즈 객체에 어떤 조건식을 적용하면 각 원소에 대해 참/거짓을 판별하여 불리언 값으로 구성된 시리즈를 반환
- 이 때 참에 해당하는 데이터 값을 따로 선택할 수 있음
titanic.head()
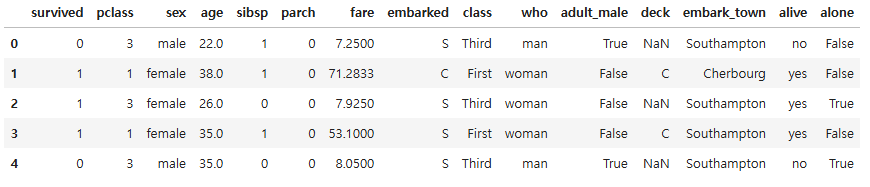
# age가 20미만인 데이터 필터링
titanic.loc[titanic["age"] < 20, :]
titanic["age"] < 20
0 False
1 False
2 False
3 False
4 False
...
886 False
887 True
888 False
889 False
890 False
Name: age, Length: 891, dtype: bool
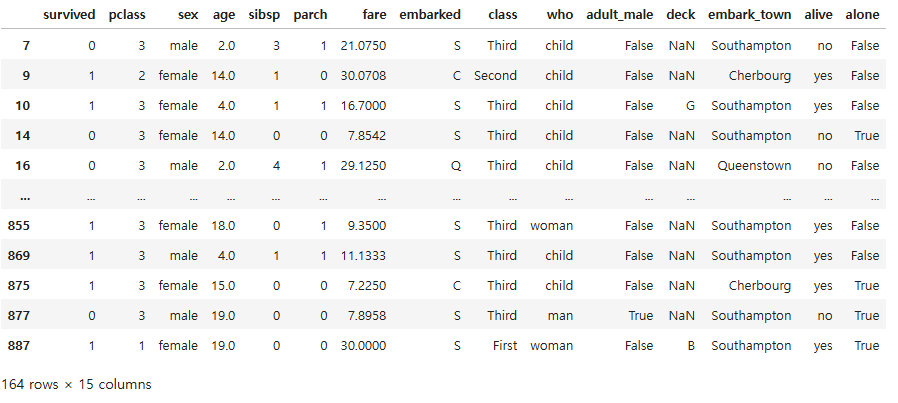
# age컬럼의 값이 10 이상이면서 20미만인 데이터 필터링
df_teenage = titanic.loc[(titanic["age"] >= 10) & (titanic["age"] < 20), :]
df_teenage.head()
(titanic["age"] >= 10) & (titanic["age"] < 20)
0 False
1 False
2 False
3 False
4 False
...
886 False
887 True
888 False
889 False
890 False
Name: age, Length: 891, dtype: bool
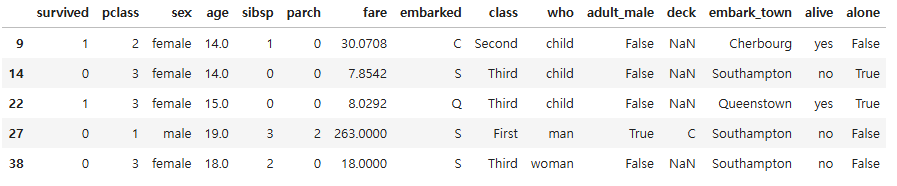
# age 컬럼의 값이 10 미만이면서 sex칼럼의 값이 "female"인 데이터 필터링
df_female_under10 = titanic.loc[(titanic["age"] < 10) & (titanic["sex"] == "female"), :]
df_female_under10.head()
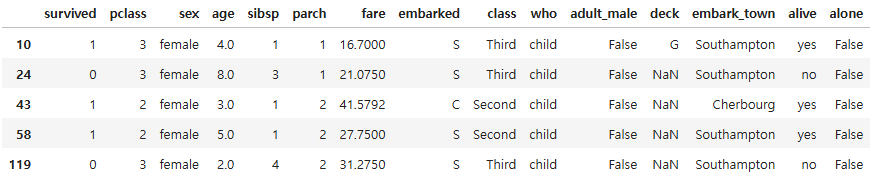
# age 컬럼의 값이 10 미만이거나 60 이상인 데이터 필터링
df_under10_morethan60 = titanic.loc[(titanic["age"] < 10) | (titanic["age"] >= 60), :]
df_under10_morethan60.head()
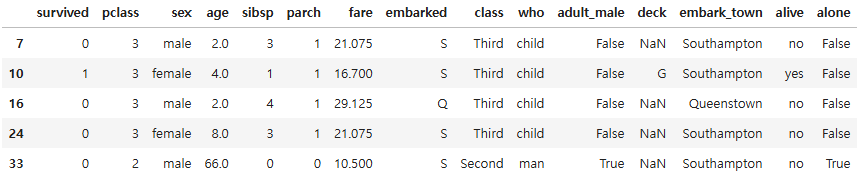
# 열을 고르는것도 가능
df_under10_morethan60 = titanic.loc[(titanic["age"] < 10) | (titanic["age"] >= 60), ["age", "sex", "alone"]]
df_under10_morethan60.head()

isin() 메소드 활용
- 데이터프레임의 열에 isin() 메소드를 적용하면 특정 값을 가진 행들을 추출할 수 있음
df_isin = titanic[titanic["sibsp"].isin([3, 4, 5])]
df_isin.head()
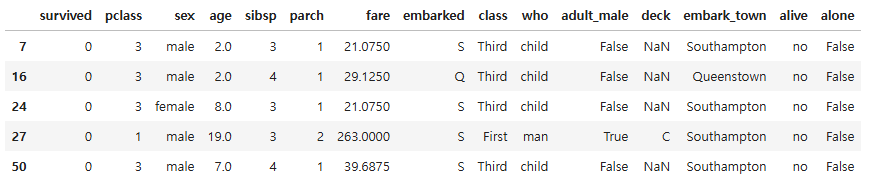
04. 데이터프레임 합치기
데이터프레임 연결
- 서로 다른 데이터프레임들의 구성 형태와 속성이 균일하다면 데이터프레임을 이어 붙여도 데이터의 일관성을 유지할 수 있음
- 기존 데이터프레임의 형태를 유지하면서 이어 붙을 때는 concat() 함수를 활용
df1 = pd.DataFrame({"a" : ["a0", "a1", "a2", "a3"],
"b" : ["b0", "b1", "b2", "b3"],
"c" : ["c0", "c1", "c2", "c3"]},
index = [0, 1, 2, 3])
df2 = pd.DataFrame({"a" : ["a2", "a3", "a4", "a5"],
"b" : ["b2", "b3", "b4", "b5"],
"c" : ["c2", "c3", "c4", "c5"]},
index = [2, 3, 4, 5])
df1

df2

# 2개의 데이터프레임을 위 아래 행 방향으로 연결
result1 = pd.concat([df1, df2], axis = 0)
result1

# 기존 행 인덱스를 무시하고 새로운 행 인덱스를 설정
result2 = pd.concat([df1, df2], axis = 0, ignore_index = True)
result2

# 좌우 열 방향으로 연결
result3 = pd.concat([df1, df2], axis = 1)
result3
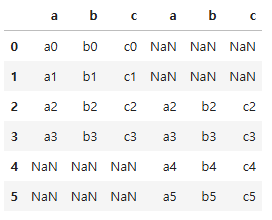
# 연결할 데이터프레임의 교집합을 기준으로 연결
result3_in = pd.concat([df1, df2], axis = 1, join = "inner")
result3_in

sr1 = pd.Series(["e0", "e1", "e2", "e3"], name = "e")
sr2 = pd.Series(["f0", "f1", "f2"], name = "f", index = [3, 4, 5])
sr3 = pd.Series(["g0", "g1", "g2", "g3"], name = "g")
df1

sr1
0 e0
1 e1
2 e2
3 e3
Name: e, dtype: object
# df1과 sr1을 좌우 열 방향으로 연결하기
result4 = pd.concat([df1, sr1], axis = 1)
result4

df2

sr2
3 f0
4 f1
5 f2
Name: f, dtype: object
# df2와 sr2를 좌우 열 방향으로 연결
result5 = pd.concat([df2, sr2], axis = 1)
result5

# sr1 과 sr3 를 좌우 열 방향으로 연결하기
result6 = pd.concat([sr1, sr3], axis = 1)
result6

# sr1 과 sr3를 행 방향으로 연결
result7 = pd.concat([sr1, sr3], axis = 0)
result7
0 e0
1 e1
2 e2
3 e3
0 g0
1 g1
2 g2
3 g3
dtype: object
데이터프레임 병합
- merge()
- SQL의 join 명령어와 비슷한 방식으로 어떤 기준에 의해 두 데이터프레임을 병합하는 개념
- 병합의 기준이 되는 열이나 인덱스를 키(Key)라고 부름
- 키가 되는 열이나 인덱스는 반드시 양쪽 데이터프레임에 모두 존재해야함
- SQL의 join 명령어와 비슷한 방식으로 어떤 기준에 의해 두 데이터프레임을 병합하는 개념
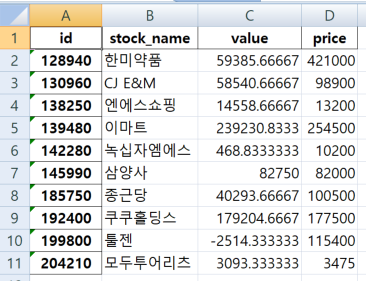
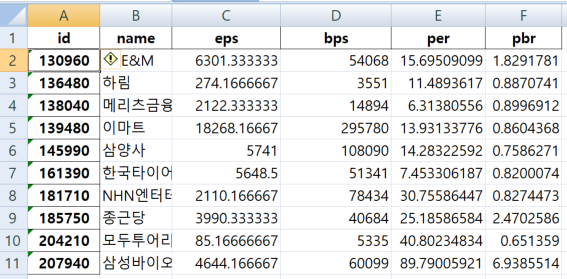
df1 = pd.read_excel("./data/stock price.xlsx")
df2 = pd.read_excel("./data/stock valuation.xlsx")
df1.head()

df2.head()
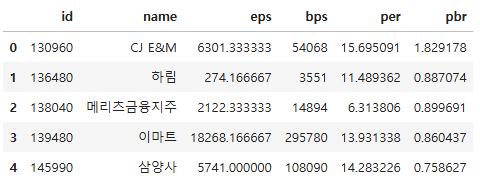
df1.shape, df2.shape
((10, 4), (10, 6))
# 데이터프레임 합치기 - 교집합
# on = None(병합기준) : 두 데이터프레임에 공통으로 속하는 모든 열을 기준으로 병합
# how = "inner" : 기준이 되는 열의 데이터가 양쪽 데이터프레임에 공통으로 존재하는 교집합일 경우에만 병합
merge_inner = pd.merge(df1, df2, on = None, how = "inner")
merge_inner
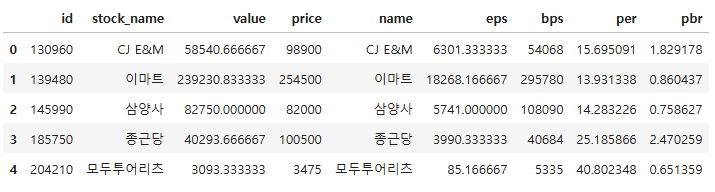
merge_inner.shape
(5, 9)
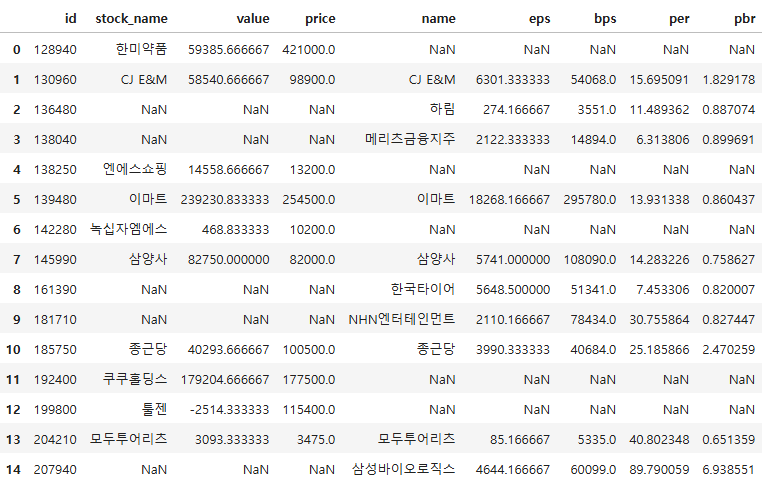
# 데이터프레임 합치기 - 합집합
# on = "id" : id열을 키로 병합
# how = "outer": 기준이 되는 id열의 데이터가 어느 한쪽에만 속하더라도 포함
merge_outer = pd.merge(df1, df2, how = "outer", on = "id")
merge_outer
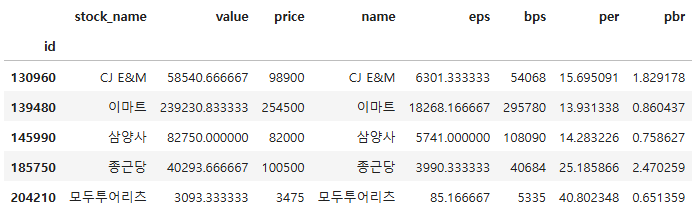
merge_left = pd.merge(df1, df2, how = "left", left_on = "stock_name", right_on = "name")
merge_left
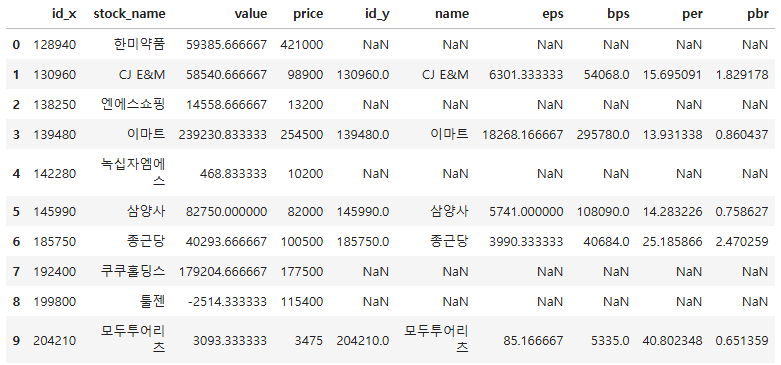
merge_right = pd.merge(df1, df2, how = "right", left_on = "stock_name", right_on = "name")
merge_right

데이터프레임 결합
- join()
- merge()함수를 기반으로 만들어져 기본 작동 방식이 비슷하지만 두 데이터프레임의 행 인덱스를 기준으로 결합하는 점이 차이점
df1 = pd.read_excel("./data/stock price.xlsx", index_col = "id")
df2 = pd.read_excel("./data/stock valuation.xlsx", index_col = "id")
df1.head()
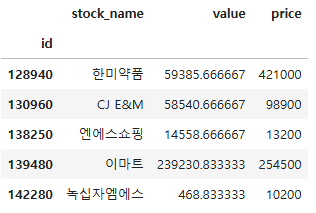
df2.head()
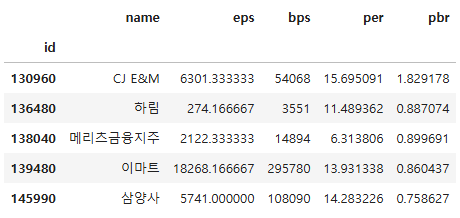
df3 = df1.join(df2)
df3
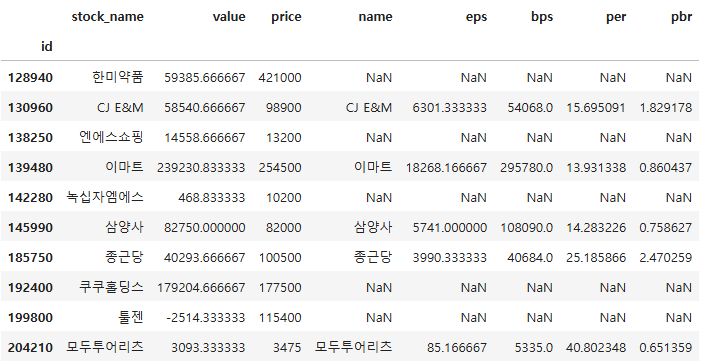
df4 = df1.join(df2, how = "inner")
df4
05. 그룹 연산
- 데이터를 특정 기준에 따라 몇 개의 그룹으로 분할하여 처리하는 것
- 데이터를 집계, 변환, 필터링하는데 효율적
- groupby()
- groupby() 메소드의 처리 과정
- 분할 : 데이터를 특정 조건에 의해 분할
- 적용 : 데이터를 집계, 변환, 필터링하는데 필요한 메소드 적용
- 결합 : 2단계의 처리 결과를 하나로 결합
- groupby() 메소드의 처리 과정
그룹 객체 만들기(분할 단계)
1개 열을 기준으로 그룹화
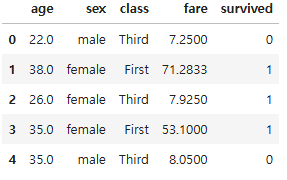
df = titanic.loc[:, ["age", "sex", "class", "fare", "survived"]]
df.head()
# class 열을 기준으로 분할
# observed = True 이면 우리가 갖고 있는 데이터만 가지고 그룹화해줌 male, female
grouped = df.groupby(["class"], observed = True)
grouped
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000213E78A8980>
df["class"].unique()
['Third', 'First', 'Second']
Categories (3, object): ['First', 'Second', 'Third']
# 그룹 객체를 iteration으로 출력
for key, group in grouped:
print("* key:", key)
print("* number:", len(group))
print(group.head())
print()
* key: ('First',)
* number: 216
age sex class fare survived
1 38.0 female First 71.2833 1
3 35.0 female First 53.1000 1
6 54.0 male First 51.8625 0
11 58.0 female First 26.5500 1
23 28.0 male First 35.5000 1
* key: ('Second',)
* number: 184
age sex class fare survived
9 14.0 female Second 30.0708 1
15 55.0 female Second 16.0000 1
17 NaN male Second 13.0000 1
20 35.0 male Second 26.0000 0
21 34.0 male Second 13.0000 1
* key: ('Third',)
* number: 491
age sex class fare survived
0 22.0 male Third 7.2500 0
2 26.0 female Third 7.9250 1
4 35.0 male Third 8.0500 0
5 NaN male Third 8.4583 0
7 2.0 male Third 21.0750 0
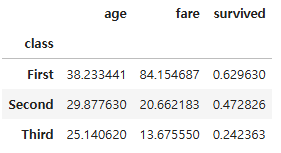
# 연산 메소드 적용
average = grouped.mean(numeric_only = True)
average
# 개별 그룹 선택하기(튜플로입력)
group3 = grouped.get_group(("Third",))
group3.head()

여러 열을 기준으로 그룹화
# class 열, sex열을 기준으로 분할
grouped_two = df.groupby(["class", "sex"], observed = True)
# grouped_two 그룹 객체를 iteration으로 출력
for key, group in grouped_two:
print("* key :", key)
print("* number : ", len(group))
print(group.head())
print()
* key : ('First', 'female')
* number : 94
age sex class fare survived
1 38.0 female First 71.2833 1
3 35.0 female First 53.1000 1
11 58.0 female First 26.5500 1
31 NaN female First 146.5208 1
52 49.0 female First 76.7292 1
* key : ('First', 'male')
* number : 122
age sex class fare survived
6 54.0 male First 51.8625 0
23 28.0 male First 35.5000 1
27 19.0 male First 263.0000 0
30 40.0 male First 27.7208 0
34 28.0 male First 82.1708 0
* key : ('Second', 'female')
* number : 76
age sex class fare survived
9 14.0 female Second 30.0708 1
15 55.0 female Second 16.0000 1
41 27.0 female Second 21.0000 0
43 3.0 female Second 41.5792 1
53 29.0 female Second 26.0000 1
* key : ('Second', 'male')
* number : 108
age sex class fare survived
17 NaN male Second 13.0 1
20 35.0 male Second 26.0 0
21 34.0 male Second 13.0 1
33 66.0 male Second 10.5 0
70 32.0 male Second 10.5 0
* key : ('Third', 'female')
* number : 144
age sex class fare survived
2 26.0 female Third 7.9250 1
8 27.0 female Third 11.1333 1
10 4.0 female Third 16.7000 1
14 14.0 female Third 7.8542 0
18 31.0 female Third 18.0000 0
* key : ('Third', 'male')
* number : 347
age sex class fare survived
0 22.0 male Third 7.2500 0
4 35.0 male Third 8.0500 0
5 NaN male Third 8.4583 0
7 2.0 male Third 21.0750 0
12 20.0 male Third 8.0500 0
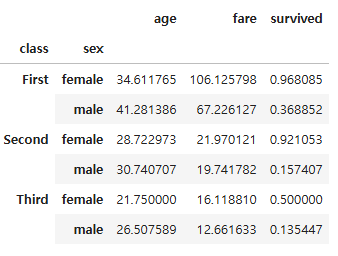
# grouped_two 그룹 객체에 연산 메소드 적용
average_two = grouped_two.mean()
average_two
type(average_two)
pandas.core.frame.DataFrame
# grouped_two 그룹 객체에서 개별 그룹 선택하기
group3f = grouped_two.get_group(("Third", "female"))
group3f.head()

그룹 연산 메소드
데이터 집계
- 그룹 객체에 다양한 연산을 적용하는 과정
- 집계 기능을 내장하고 있는 판다스 기본 함수
- mean()
- max()
- min()
- sum()
- count()
- size()
- var()
- std()
- describe()
- info()
df.head()
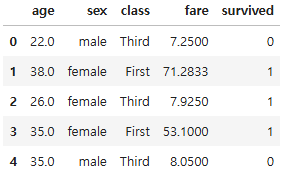
grouped = df.groupby("class", observed = True)
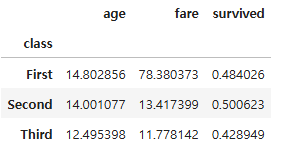
# 각 그룹에 대한 모든 열의 표준편차를 집계하여 데이터프레임으로 반환
std_all = grouped.std(numeric_only = True)
std_all
# 각 그룹에 대한 fare 열의 표준편차
std_fare = grouped["fare"].std()
std_fare
class
First 78.380373
Second 13.417399
Third 11.778142
Name: fare, dtype: float64
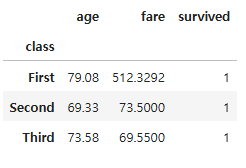
# 그룹 객체에 agg() 메소드 적용 - 사용자 정의 함수를 인수로 전달
def min_max(x):
return x.max() - x.min()
- 집계 연산을 처리하는 사용자 정의 함수를 그룹 객체에 적용하기 위해서는 agg() 메소드를 사용
# 각 그룹의 최댓값과 최솟값의 차이를 계산하여 그룹별로 집계
agg_minmax = grouped[["age", "fare", "survived"]].agg(min_max)
agg_minmax
- 동시에 여러 개의 함수를 사용하여 각 그룹별 데이터에 대한 집계 연산을 처리
- 각각의 열에 여러 개의 함수를 일괄 적용할 때는 리스트 형태로 인수를 전달
- 열마다 다른 종류의 함수를 전달하려면 {열 : 함수} 형태의 딕셔너리를 전달
# 여러 함수를 각 열에 동일하게 적용하여 집계
agg_all = grouped.agg(["min", "max"])
agg_all

# 각 열마다 다른 함수를 적용하여 집계
agg_sep = grouped.agg({"fare" : ["min", "max"], "age" : "mean"})
agg_sep
그룹 객체 필터링
- 그룹 객체에 filter() 메소드를 적용할 때 조건식을 가진 함수를 전달하여 조건이 참인 그룹만을 필터링
# 데이터 개수가 200개 이상인 그룹만을 필터링하여 데이터프레임으로 변환
grouped_filter = grouped.filter(lambda x: len(x) >= 200)
grouped_filter
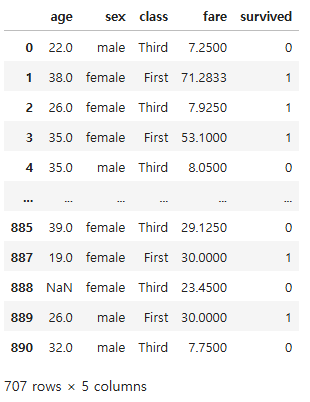
grouped.count()

grouped_filter["class"].unique()
['Third', 'First']
Categories (3, object): ['First', 'Second', 'Third']
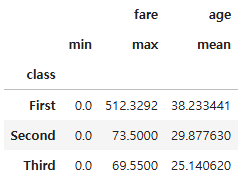
#age 열의 평균이 30보다 작은 그룹만을 필터링하여 데이터프레임으로 반환
age_filter = grouped.filter(lambda x: x["age"].mean() < 30)
age_filter
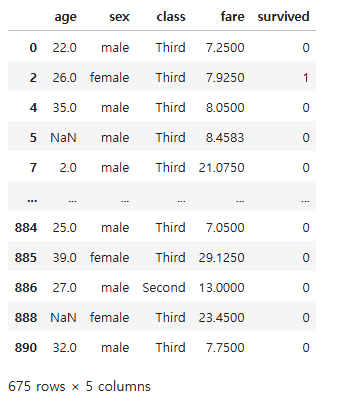
grouped["age"].mean()
class
First 38.233441
Second 29.877630
Third 25.140620
Name: age, dtype: float64
멀티 인덱스
- 행 인덱스를 여러 레벨로 구현하는 것
# class열, sex열을 기준으로 분할
grouped = df.groupby(["class", "sex"], observed = True)
gdf = grouped.mean()
gdf
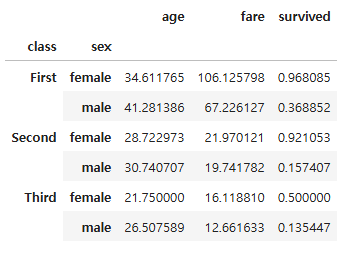
# class 값이 First인 행을 선택하여 출력
gdf.loc["First"]

# class 값이 First이고, sex값이 female인 행을 선택하여 출력
gdf.loc[("First", "female")]
age 34.611765
fare 106.125798
survived 0.968085
Name: (First, female), dtype: float64
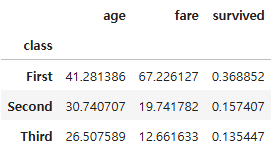
#sex 값이 male인 행을 선택하여 출력
gdf.xs("male", level = "sex")
gdf.index
MultiIndex([( 'First', 'female'),
( 'First', 'male'),
('Second', 'female'),
('Second', 'male'),
( 'Third', 'female'),
( 'Third', 'male')],
names=['class', 'sex'])
피벗
- pivot_table()
- 엑셀에서 사용하는 피벗테이블과 비슷한 기능
- 커다란 표의 데이터를 요약하는 통계표
df.head()

# 행, 열, 값, 집계에 사용할 열을 1개씩 지정 - 평균 집계
pdf1 = pd.pivot_table(df,
index = "class", # 행 위치에 들어갈 열
columns = "sex", # 열 위치에 들어갈 열
values = "age", #데이터로 사용할 열
aggfunc = "mean", # 데이터 집계 함수
observed = True)
pdf1

# 값에 적용하는 집계 함수를 2개 이상 지정 가능 - 생존율, 생존자 수 집계
pdf2 = pd.pivot_table(df,
index = "class",
columns = "sex",
values = "survived",
aggfunc = ["mean", "sum"],
observed = True)
pdf2

# 행, 열, 값에 사용할 열을 2개 이상 지정 가능 - 평균 나이, 최대 요금 집계
pdf3 = pd.pivot_table(df,
index = ["class", "sex"],
columns = "survived",
values = ["age", "fare"],
aggfunc = ["mean", "max"],
observed = True)
pdf3

'05_Pandas' 카테고리의 다른 글
| 05-2_연습문제_euro2012 (0) | 2025.03.06 |
|---|---|
| 05-1_연습문제_student_alchol_consumption (0) | 2025.03.06 |
| 04-1_연습문제_iris (0) | 2025.03.06 |
| 04_데이터 전처리 (1) | 2025.03.06 |
| 03-1_연습문제_occupation (0) | 2025.03.05 |