728x90
import pandas as pd
문제1. user_id를 인덱스로 사용한 데이터프레임 읽기

df = pd.read_csv("./data/occupation.tsv", sep='|', index_col = 'user_id')
문제2. 상위 25개 행 확인
df.head(25)
문제3. 하위 10개 행 확인
df.tail(10)
문제4. 데이터의 행 수 확인
df.shape[0]
943
len(df)
943
문제5. 컬럼 수 확인
df.shape[1]
4
len(df.columns)
4
문제6. 컬럼명 확인
df.columns
Index(['age', 'gender', 'occupation', 'zip_code'], dtype='object')
문제7. 데이터 인덱스 확인
df.index
Index([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
...
934, 935, 936, 937, 938, 939, 940, 941, 942, 943],
dtype='int64', name='user_id', length=943)
문제8. 각 컬럼의 자료형 확인
df.dtypes
age int64
gender object
occupation object
zip_code object
dtype: object
문제9. occupation 컬럼 추출
df['occupation']
user_id
1 technician
2 other
3 writer
4 technician
5 other
...
939 student
940 administrator
941 student
942 librarian
943 student
Name: occupation, Length: 943, dtype: object
문제10. occupation 컬럼의 고유값 수 확인
df['occupation'].value_counts()
occupation
student 196
other 105
educator 95
administrator 79
engineer 67
programmer 66
librarian 51
writer 45
executive 32
scientist 31
artist 28
technician 27
marketing 26
entertainment 18
healthcare 16
retired 14
lawyer 12
salesman 12
none 9
homemaker 7
doctor 7
Name: count, dtype: int64
df['occupation'].value_counts().count()
21
len(df['occupation'].value_counts())
21
df['occupation'].unique()
array(['technician', 'other', 'writer', 'executive', 'administrator',
'student', 'lawyer', 'educator', 'scientist', 'entertainment',
'programmer', 'librarian', 'homemaker', 'artist', 'engineer',
'marketing', 'none', 'healthcare', 'retired', 'salesman', 'doctor'],
dtype=object)
len(df['occupation'].unique())
21
df['occupation'].nunique()
21
문제11. occupation 컬럼의 최빈값 확인
df['occupation'].value_counts().index[0]
'student'
문제12. 수치형 컬럼의 기술 통계 확인
df.describe()

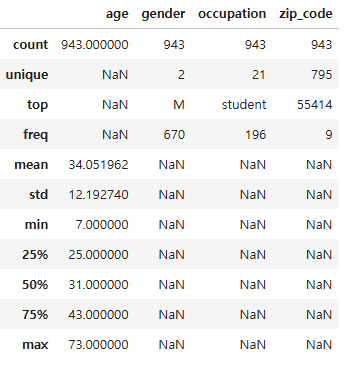
문제13. 모든 컬럼의 기술 통계 확인
df.describe(include = 'all')
문제14. occupation 컬럼의 기술 통계 확인
df['occupation'].describe()
count 943
unique 21
top student
freq 196
Name: occupation, dtype: object
문제15. age컬럼의 평균 구하기¶
- 단, 소수점 이하는 반올림
round(df['age'].mean())
34
문제16. age컬럼에서 빈도가 가장 낮은 고유값 5개 확인
df['age'].value_counts().tail(5).index
Index([7, 66, 11, 10, 73], dtype='int64', name='age')728x90
'05_Pandas' 카테고리의 다른 글
| 04-1_연습문제_iris (0) | 2025.03.06 |
|---|---|
| 04_데이터 전처리 (1) | 2025.03.06 |
| 03_데이터 탐색 (1) | 2025.03.05 |
| 02_Pandas_데이터 입출력 (0) | 2025.03.05 |
| 01-1_연습문제_포켓몬 (0) | 2025.03.04 |