728x90
분석 목표
- 여러 제조사별 무선청소기의 가격과 성능에 대한 데이터를 수집하고 분석하여 각각의 상황에 맞는 제품군 파악
from selenium import webdriver
from seleniuhttp://m.webdriver.common.by import By
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
# Windows용 한글 폰트 오류 해결
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname = font_path).get_name()
rc("font", family = font_name)
데이터 수집
url = "https://prod.danawa.com/list/?cate=102207&shortcutKeyword=%EB%AC%B4%EC%84%A0%EC%B2%AD%EC%86%8C%EA%B8%B0"
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(3)
soup = BeautifulSoup(driver.page_source, "lxml")
prod_items = soup.select("div.main_prodlist li.prod_item")
len(prod_items)
30
# 상품명
prod_items[0].select_one("p.prod_name > a").string.strip()
'아이닉 i50 아이타워'
# 스펙 목록
prod_items[0].select_one("div.spec-box--full > div.spec_list").text.strip()
'핸디스틱청소기/무선/흡입형/흡입력: 520W/흡입력: 45,000Pa/스테이션 기능: 먼지비움, 충전, 액서서리수납, 스탠드거치/브러쉬: 전방향바닥/침구/솔형/틈새/먼지봉투: 1.5L/[배터리] 사용시간: 1시간05분(최대)/분리형(1개)/[청소] LED라이트/UV살균/BLDC모터/헤파필터/무게: 2.7kg/크기(가로x세로x깊이): 250x1040x260mm'
# 가격
prod_items[5].select_one("p.price_sect strong").string.replace(",", "").strip()
'1170000'
prod_data = {"상품명" : [],
"스펙목록" : [],
"가격" : []}
prod_items = soup.select("div.main_prodlist li.prod_item")
for item in prod_items:
# 상품명
title = item.select_one("p.prod_name > a").string.strip()
# 스펙 목록
spec_list = item.select_one("div.spec-box--full > div.spec_list").text.strip()
# 가격
price = item.select_one("p.price_sect strong").string.replace(",", "").strip()
prod_data["상품명"].append(title)
prod_data["스펙목록"].append(spec_list)
prod_data["가격"].append(price)
len(prod_data["상품명"]), len(prod_data["스펙목록"]), len(prod_data["가격"])
(30, 30, 30)
prod_data["상품명"][:5]
['아이닉 i50 아이타워',
'LG전자 오브제컬렉션 코드제로 A9S AU927CWD',
'LG전자 코드제로 A9 Air AS9000WR',
'LG전자 오브제컬렉션 코드제로 A9S AX9604WE',
'LG전자 오브제컬렉션 코드제로 A9S AX958BWE']
prod_data["스펙목록"][:5]
['핸디스틱청소기/무선/흡입형/흡입력: 520W/흡입력: 45,000Pa/스테이션 기능: 먼지비움, 충전, 액서서리수납, 스탠드거치/브러쉬: 전방향바닥/침구/솔형/틈새/먼지봉투: 1.5L/[배터리] 사용시간: 1시간05분(최대)/분리형(1개)/[청소] LED라이트/UV살균/BLDC모터/헤파필터/무게: 2.7kg/크기(가로x세로x깊이): 250x1040x260mm',
'핸디스틱청소기/무선/흡입+물걸레(동시)/흡입력: 260W/스테이션 기능: 먼지비움, 충전, UVC LED, 액서서리수납, 스탠드거치/먼지비움시간: 30초/브러쉬: 바닥/물걸레: 일반/솔형/틈새/먼지봉투: 2.5L/[배터리] 사용시간: 1시간(최대)/분리형(1개)/리튬이온/[청소] 싸이클론흡입/자동물공급/스마트인버터모터/워셔블헤파필터/무게: 2.5kg/크기(가로x세로x깊이): 250x1120x260mm',
'핸디스틱청소기/무선/흡입형/흡입력: 150W/스테이션 기능: 충전, 스탠드거치, 액서서리&배터리거치/브러쉬: 바닥/솔형/틈새/틈새(내장형)/[배터리] 사용시간: 40분(최대)/분리형(1개)/리튬이온/[청소] 싸이클론흡입/스마트인버터모터/무게: 1.97kg/크기(가로x세로x깊이): 251x1026x242mm',
'핸디스틱청소기/무선/흡입형/흡입력: 250W/스테이션 기능: 먼지비움, 충전, UVC LED, 액서서리수납, 스탠드거치/먼지비움시간: 30초/브러쉬: 와이드바닥/물걸레: 별매/솔형/틈새/먼지봉투: 2.5L/[배터리] 사용시간: 30분(최대)/분리형(1개)/리튬이온/[청소] LED라이트/싸이클론흡입/스마트인버터모터/워셔블헤파필터/무게: 2.47kg/크기(가로x세로x깊이): 300x1120x245mm',
'핸디스틱청소기/무선/흡입+물걸레(동시)/흡입력: 280W/스테이션 기능: 먼지비움, 충전, 액서서리수납, 스탠드거치/먼지비움시간: 30초/브러쉬: 와이드바닥/물걸레: 스팀, 고온, 일반/침구/솔형/틈새/먼지봉투: 2.5L/[배터리] 사용시간: 30분(최대)/분리형(2개)/리튬이온/[청소] LED라이트/싸이클론흡입/오토스탑앤고/자동물공급/스마트인버터모터/워셔블헤파필터/무게: 2.49kg/크기(가로x세로x깊이): 300x1100x245mm']
prod_data["가격"][:5]
['296980', '702340', '363080', '689370', '978500']
# 10페이지까지 반복
prod_data = {"상품명" : [],
"스펙목록" : [],
"가격" : []}
driver = webdriver.Chrome()
driver.get(url)
for i in range(10):
time.sleep(2)
soup = BeautifulSoup(driver.page_source, "lxml")
prod_items = soup.select("div.main_prodlist li.prod_item")
for item in prod_items:
# 상품명
title = item.select_one("p.prod_name > a").string.strip()
# 스펙 목록
spec_list = item.select_one("div.spec-box--full > div.spec_list").text.strip()
# 가격
price = item.select_one("p.price_sect strong").string.replace(",", "").strip()
prod_data["상품명"].append(title)
prod_data["스펙목록"].append(spec_list)
prod_data["가격"].append(price)
if i != 9:
driver.find_element(By.CSS_SELECTOR, "a.now_on + a").click()
데이터 전처리
데이터 확인
df = pd.DataFrame(prod_data)
df.head()

df.shape
(300, 3)
df.to_csv("./data/danawa.csv", index = False)
# 250324 저장한 데이터를 불러옴
df = pd.read_csv("./data/danawa.csv")
df.dtypes
상품명 object
스펙목록 object
가격 object
dtype: object
# 스펙목록 전처리
def clean_text(text):
text = text.replace("\n", "")
text = text.replace("\t", "")
text = text.replace(" ", "")
return text
df["스펙목록"] = df["스펙목록"].map(clean_text)
df.head()
df["가격"].unique()
array(['296980', '702340', '363080', '689370', '978500', '1170000',
'145082', '635200', '462570', '639610', '205560', '1293560',
'696000', '772430', '1057890', '361890', '189770', '583810',
'494900', '649800', '724000', '728880', '423660', '328830',
'299000', '1109630', '805000', '179000', '595830', '797990',
'820800', '491110', '424480', '190600', '565890', '67790', '87900',
'1060750', '449100', '459620', '219100', '827690', '744920',
'69000', '200630', '109110', '459860', '800990', '1259050',
'39590', '364900', '39900', '1151720', '423200', '515120',
'324570', '303340', '1009780', '29240', '99000', '832950',
'198000', '960300', '1023110', '42780', '61020', '442170',
'111500', '453890', '904150', '148570', '743870', '236900',
'148000', '81530', '205730', '128000', '315280', '803000',
'159000', '393970', '349000', '145000', '230000', '265050',
'634700', '158000', '580310', '219000', '1104760', '759960',
'119000', '93060', '186000', '258900', '44630', '106000', '117000',
'219450', '94000', '104890', '209470', '197690', '199510',
'259000', '554600', '269700', '199000', '396880', '104900',
'523570', '295640', '814000', '52890', '178000', '118000',
'348750', '512250', '691780', '292080', '907960', '154850',
'799590', '129000', '173230', '1150990', '716680', '138990',
'1177000', '42750', '426000', '40000', '579000', '1280450',
'80060', '695410', '425180', '750000', '502200', '689700',
'942410', '98440', '24090', '194750', '444870', '1119980',
'720000', '928020', '500450', '189000', '510000', '57000',
'366500', '281680', '339000', '249000', '189800', '98000',
'636760', '168990', '176000', '402570', '1136920', '549000',
'1168990', '192450', '95400', '418990', '70400', '112480',
'369550', '274500', '1197990', '557650', '46800', '49770',
'290000', '117870', '650000', '949980', '68940', '187060',
'789990', '149000', '66210', '63900', '22700', '82700', '999000',
'319800', '469000', '276780', '462060', '160600', '857000',
'629000', '47800', '155000', '379620', '30690', '289000', '49800',
'1320470', '102490', '664280', '467350', '244000', '519000',
'269000', '154750', '137730', '1072950', '172050', '288840',
'1000000', '374120', '1727460', '94050', '116100', '175750',
'229800', '56110', '711760', '50000', '46910', '108990', '178990',
'735420', '640000', '297570', '357520', '185730', '279500',
'754120', '124000', '1061620', '44900', '473960', '473590',
'1149220', '9500', '142080', '329000', '93010', '42900', '649000',
'1115090', '957100', '50940', '23730', '52000', '577250', '34670',
'775350', '가격비교예정', '84600', '367000', '724500', '1120000',
'57690', '456690', '32900', '74900', '35340', '1569990', '104250',
'948000', '183370', '215720', '294190', '658450', '818670',
'618990', '438870', '243040', '135900', '598990', '198990',
'59800', '37990'], dtype=object)
df = df[df["가격"] != "가격비교예정"]
# 가격 컬럼을 정수형으로 변환
df["가격"] = df["가격"].astype(int)
df.dtypes
상품명 object
스펙목록 object
가격 int32
dtype: object
회사명, 모델명 정리
- 상품명 데이터는 회사명 + 모델명의 형식임
- 브랜드와 모델명으로 분리
df.iloc[0, 0].split(" ", 1) # 첫 번째 공백에 대해서만 구분하도록
['아이닉', 'i50 아이타워']
titles = df["상품명"].str.split(n = 1)
df["회사명"] = titles.str[0]
df["제품"] = titles.str[1]
df.head()
df = df.drop("상품명", axis = 1)
df.head()

스펙 목록 살펴보기
df.iloc[0, 0]
'핸디스틱청소기/무선/흡입형/흡입력:520W/흡입력:45,000Pa/스테이션기능:먼지비움,충전,액서서리수납,스탠드거치/브러쉬:전방향바닥/침구/솔형/틈새/먼지봉투:1.5L/[배터리]사용시간:1시간05분(최대)/분리형(1개)/[청소]LED라이트/UV살균/BLDC모터/헤파필터/무게:2.7kg/크기(가로x세로x깊이):250x1040x260mmdf.iloc[1, 0].split("/")
['핸디스틱청소기',
'무선',
'흡입+물걸레(동시)',
'흡입력:260W',
'스테이션기능:먼지비움,충전,UVCLED,액서서리수납,스탠드거치',
'먼지비움시간:30초',
'브러쉬:바닥',
'물걸레:일반',
'솔형',
'틈새',
'먼지봉투:2.5L',
'[배터리]사용시간:1시간(최대)',
'분리형(1개)',
'리튬이온',
'[청소]싸이클론흡입',
'자동물공급',
'스마트인버터모터',
'워셔블헤파필터',
'무게:2.5kg',
'크기(가로x세로x깊이):250x1120x260mm']- 카테고리 : 스펙 리스트의 첫 번째 항목에 위치
- 사용시간 : "사용시간: 00시간" 과 같이 사용시간 이라는 문구가 명시되어 있음
- 흡입력 : "흡입력:000W" 와 같이 흡입력 이라는 문구가 명시되어 있음\
# test
spec_list = df.iloc[0, 0].split("/")
category = spec_list[0]
category
'핸디스틱청소기'
for spec in spec_list:
if "사용시간" in spec:
use_time_spec = spec
use_time_spec = use_time_spec.split(":")[1]
elif "흡입력" in spec:
suction_spec = spec
suction_spec = suction_spec.split(":")[1]
print(use_time_spec)
print(suction_spec)
1시간05분(최대)
45,000Pa
# 반복문
category_list = []
use_time_list = []
suction_list = []
for spec_data in df["스펙목록"]:
# / 기준으로 분리
spec_list = spec_data.split("/")
# 카테고리 추출
category = spec_list[0]
category_list.append(category)
# 사용시간, 흡입력 추출
use_time_spec = None
suction_spec = None
for spec in spec_list:
if "사용시간" in spec:
use_time_spec = spec.split(":")[1]
elif "흡입력" in spec:
suction_spec = spec.split(":")[1]
use_time_list.append(use_time_spec)
suction_list.append(suction_spec)
category_list[:5]
['핸디스틱청소기', '핸디스틱청소기', '핸디스틱청소기', '핸디스틱청소기', '핸디스틱청소기']
use_time_list[:5]
['1시간05분(최대)', '1시간(최대)', '40분(최대)', '30분(최대)', '30분(최대)']
suction_list[:5]
['45,000Pa', '260W', '150W', '250W', '280W']
- 숫자형 데이터가 아니고 단위 통일이 안 되어 있어서 통일시켜줘야함
사용시간 단위 통일
- 분 단위로 통일
- "시간" 단어가 있으면
- "시간" 앞의 숫자를 추출한 뒤 60을 곱해 사용시간에 더함
- "시간" 뒤의 글자에서 "분" 글자 앞의 숫자를 추출해서 사용시간에 더함
- "시간" 단어가 없으면
- "분" 글자 앞의 숫자를 추출해서 사용시간에 더함
- 위 방식으로 계산되지 않을 경우 예외로 처리
- "시간" 단어가 있으면
def convert_time_minute(time):
try:
if "시간" in time:
hour = time.split("시간")[0]
if "분" in time:
minute = time.split("시간")[-1].split("분")[0]
else:
minute = 0
else:
hour = 0
minute = time.split("분")[0]
if "~" in minute:
minute = minute.split("~")[1]
return int(hour) * 60 + int(minute)
except:
return None
# 테스트1
convert_time_minute(use_time_list[0])
65
# 테스트2
for i in use_time_list[:10]:
print(i)
print(convert_time_minute(i))
1시간05분(최대)
65
1시간(최대)
60
40분(최대)
40
30분(최대)
30
30분(최대)
30
30분(최대)
30
50분(최대)
50
1시간(최대)
60
1시간(최대)
60
1시간(최대)
60
new_use_time_list = []
for i in use_time_list:
new_use_time_list.append(convert_time_minute(i))
df["사용시간"] = new_use_time_list
df.head()

흡입력 단위 통일
- 사용하는 단위는 AW, W, PA
- 단위간 환산은 대략(1W = 1AW = 100PA)
- 위 전환식으로 AW기준으로 단위를 통일
- 전처리 과정
- 모든 알파벳 문자를 대문자로 수정
- 흡입력에 "AW"나 "W" 글자가 있다면
- 흡입력에서 "A"와 "W"를 삭제
- ","를 삭제한 뒤 숫자형 데이터로 변환
- 흡입력에 "PA"글자가 있다면
- 흡입력에서 "PA"글자를 삭제
- "," 를 삭제한 뒤 정수로 변환하고 100으로 나눔
- 흡입력 값이 비어 있거나 단위 변환시 에러가 날 경우 예외로 처리
def get_suction(value):
try:
value = value.upper()
if "W" in value:
result = value.replace("A", "").replace("W", "")
result = int(result.replace(",", ""))
elif "PA" in value:
result = value.replace("PA", "")
result = int(result.replace(",", "")) / 100
else:
result = None
return result
except:
return None
for i in suction_list[:10]:
print(get_suction(i))
450.0
260
150
250
280
250
None
260
130
220
new_suction_list = []
for power in suction_list:
new_suction_list.append(get_suction(power))
df["흡입력"] = new_suction_list
df.head()

df["카테고리"] = category_list
df.head()
pd_data = df[["카테고리", "회사명", "제품", "가격", "사용시간", "흡입력"]]
pd_data.head()

pd_data["카테고리"].value_counts()
카테고리
핸디스틱청소기 274
핸디청소기 19
스틱청소기 6
Name: count, dtype: int64
- 핸디스틱 청소기에 대해서만 분석
pd_data_final = pd_data[pd_data["카테고리"] == "핸디스틱청소기"]
pd_data_final.head()

pd_data_final.shape
(274, 6)
pd_data_final.to_excel("./data/danawa_data_final.xlsx", index = False)
데이터 확인
pd_data_final.sort_values("흡입력", ascending = False).head()

pd_data_final.sort_values("사용시간", ascending = False).head()

pd_data_final.sort_values(["사용시간", "흡입력"], ascending = False).head()

pd_data_final.sort_values(["사용시간", "흡입력"], ascending = False).head()

가성비 좋은 제품 찾아보기
- 가성비가 좋다: 가격 대비 성능이 우수하다
- 각 모델을 가격, 흡입력, 사용시간의 평균값과 비교
price_mean_value = pd_data_final["가격"].mean()
suction_mean_value = pd_data_final["흡입력"].mean()
use_time_mean_value = pd_data_final["사용시간"].mean()
print(price_mean_value)
print(suction_mean_value)
print(use_time_mean_value)
432645.8832116788
216.53669724770643
43.43181818181818
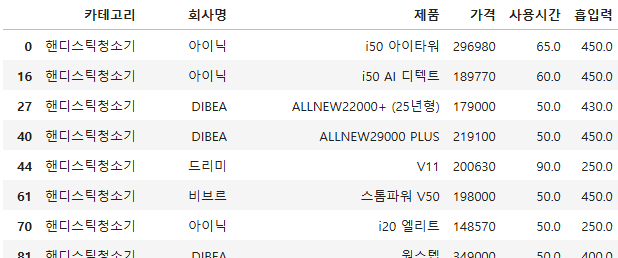
- 가성비 좋은 제품: 가격 43만원 이하, 흡입력 217이상, 사용시간 44분 이상
condition_data = pd_data_final[
(pd_data_final["가격"] <= price_mean_value) &
(pd_data_final["흡입력"] >= suction_mean_value) &
(pd_data_final["사용시간"] >= use_time_mean_value)
]
condition_data
...
# 가격이 낮은 순으로 정렬
condition_data.sort_values("가격", ascending = True)

...
condition_data["회사명"].value_counts()
회사명
아이닉 6
DIBEA 6
드리미 2
비브르 2
캐치웰 2
신일전자 1
에어메이드 1
비즈포비즈 1
쿠쿠전자 1
샤오미 1
아토케어 1
차이슨 1
퍼피유 1
에버튼하우스 1
JONR 1
Name: count, dtype: int64- DIBEA, 아이닉 제품들이 가성비가 좋음
데이터 시각화
pd_data_final.isna().sum()
카테고리 0
회사명 0
제품 0
가격 0
사용시간 10
흡입력 56
dtype: int64
# 결측치 있는 행 제거
chart_data = pd_data_final.dropna(axis = 0)
chart_data.shape
(209, 6)
# 흡입력, 사용시간의 최댓값/평균값 정리
suction_max_value = chart_data["흡입력"].max()
suction_mean_value = chart_data["흡입력"].mean()
suction_min_value = chart_data["흡입력"].min()
use_time_max_value = chart_data["사용시간"].max()
use_time_mean_value = chart_data["사용시간"].mean()
use_time_min_value = chart_data["사용시간"].min()
print(suction_max_value)
print(suction_mean_value)
print(suction_min_value)
print(use_time_max_value)
print(use_time_mean_value)
print(use_time_min_value)
600.0
215.28708133971293
22.0
100.0
44.51196172248804
9.0plt.figure(figsize = (20, 10))
plt.title("무선 핸디스틱청소기 차트")
sns.scatterplot(x = "흡입력", y = "사용시간", size = "가격", hue = chart_data["회사명"],
data = chart_data, sizes = (10, 1000), legend = False)
plt.plot([suction_min_value, suction_max_value],
[use_time_mean_value, use_time_mean_value],
"r--",
lw = 1)
plt.plot([suction_mean_value, suction_mean_value],
[use_time_min_value, use_time_max_value],
"r--",
lw = 1)
plt.show()

- 사용시간이 길고 흡입력이 큰 제품이 가격이 높아지는 경향이 있음
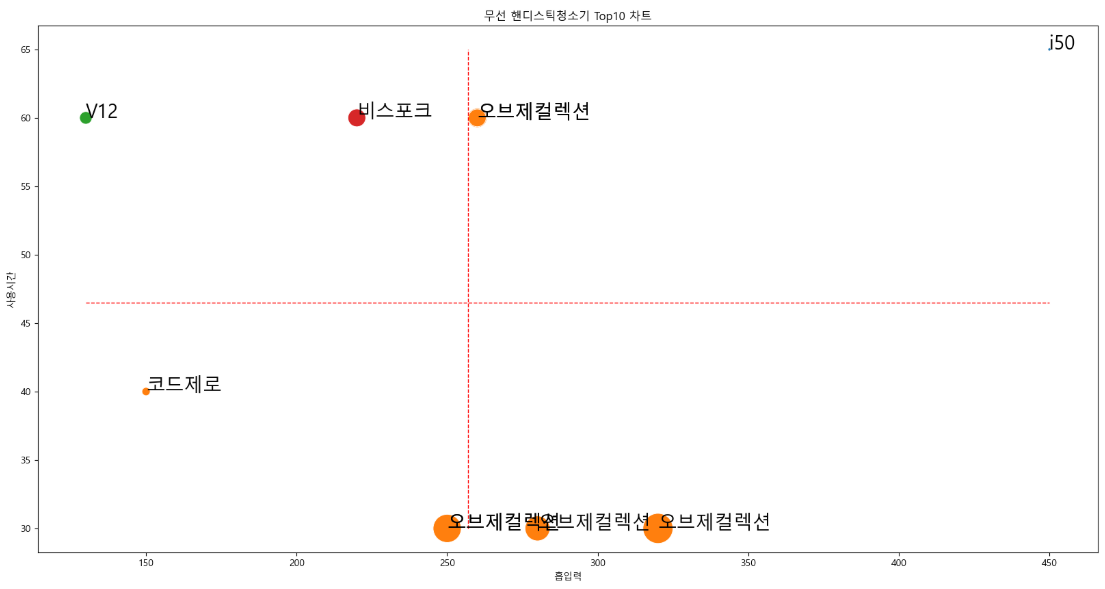
인기제품 10개 모델 시각화
chart_data_selected = chart_data[:10]
chart_data_selected

suction_max_value = chart_data_selected["흡입력"].max()
suction_mean_value = chart_data_selected["흡입력"].mean()
suction_min_value = chart_data_selected["흡입력"].min()
use_time_max_value = chart_data_selected["사용시간"].max()
use_time_mean_value = chart_data_selected["사용시간"].mean()
use_time_min_value = chart_data_selected["사용시간"].min()
plt.figure(figsize = (20, 10))
plt.title("무선 핸디스틱청소기 Top10 차트")
sns.scatterplot(x = "흡입력", y = "사용시간", size = "가격", hue = chart_data_selected["회사명"],
data = chart_data_selected, sizes = (10, 1000), legend = False)
# 회사 종류가 적으므로 legend = True로 변경
plt.plot([suction_min_value, suction_max_value],
[use_time_mean_value, use_time_mean_value],
"r--",
lw = 1)
plt.plot([suction_mean_value, suction_mean_value],
[use_time_min_value, use_time_max_value],
"r--",
lw = 1)
# 각 점에 텍스트를 찍어서 표현
for idx, row in chart_data_selected.iterrows():
x = row["흡입력"]
y = row["사용시간"]
s = row["제품"].split(" ")[0]
plt.text(x, y, s, size = 20)
plt.show()
'07_Data_Analysis' 카테고리의 다른 글
| 20_별다방, 서울시 데이터 (2) | 2025.03.21 |
|---|---|
| 19_Wordcloud, Polium_제주도 맛집 데이터 (6) | 2025.03.20 |
| 18_외국인 관광객 데이터 분석 (0) | 2025.03.20 |
| 17_유투브 랭킹 데이터 분석 (0) | 2025.03.19 |
| 16_기온 데이터 분석 (0) | 2025.03.19 |