728x90
별다방, 서울시 데이터를 통해 인구수별 별다방 매장 수를 분석
from selenium import webdriver
from seleniuhttp://m.webdriver.common.by import By
from bs4 import BeautifulSoup
from seleniuhttp://m.webdriver.common.keys import Keys
import time
from seleniuhttp://m.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import ElementNotInteractableException
import pandas as pd
import folium
import json
# 통계검정을 위해 import
from scipy import stats
데이터 수집
별다방 데이터 수집
url = "https://www.starbucks.co.kr/store/store_map.do?disp=locale"
driver = webdriver.Chrome()
driver.get(url)
# 시도 버튼 정보 올 때까지 명시적 대기
WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "a.set_sido_cd_btn"))
)
# 시도 버튼 리스트
sido = driver.find_elements(By.CSS_SELECTOR, "a.set_sido_cd_btn")
# 시도(서울) 클릭
sido[0].click()
# 구군 명시적 대기
WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "a.set_gugun_cd_btn"))
)
# 구군 버튼 리스트
gugun = driver.find_elements(By.CSS_SELECTOR, "a.set_gugun_cd_btn")
# 구군 클릭
target = gugun[0]
try:
target.click()
except ElementNotInteractableException as e:
driver.execute_script("arguments[0].click();", target)
# 매장 리스트 명시적 대기
WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "li.quickResultLstCon"))
)
soup = BeautifulSoup(driver.page_source, "lxml")
stores = soup.select("li.quickResultLstCon > strong")
for i in stores:
print(i.string)
역삼아레나빌딩
논현역사거리
신사역성일빌딩
국기원사거리
대치재경빌딩
봉은사역
압구정윤성빌딩
코엑스별마당
삼성역섬유센터R
압구정R
수서역R
양재강남빌딩R
선릉동신빌딩R
봉은사로선정릉
강남오거리
스타필드코엑스몰R
...
len(stores)
634
stores = soup.select("li.quickResultLstCon")
# 매장명
stores[0].select_one("strong").string.strip()
'역삼아레나빌딩'
# 위도
stores[0].get("data-lat", "")
'37.501087'
# 경도
stores[0].get("data-long", "")
'127.043069'
# 매장 타입
stores[0].select_one("i").get("class", "")[0][4:]
'general'
# 주소
stores[0].select_one("p.result_details").next_element
'서울특별시 강남구 언주로 425 (역삼동)'
# 전화번호
stores[0].select_one("p.result_details").next_element.next_element.next_element
'1522-3232'
starbucks = {"매장명" : [],
"위도" : [],
"경도" : [],
"매장타입" : [],
"주소" : [],
"전화번호" : []}
for i in stores:
starbucks["매장명"].append(i.select_one("strong").text.strip())
starbucks["위도"].append(i.get("data-lat", ""))
starbucks["경도"].append(i.get("data-long", ""))
starbucks["매장타입"].append(i.select_one("i").get("class", "")[0][4:])
starbucks["주소"].append(i.select_one("p.result_details").next_element)
starbucks["전화번호"].append(i.select_one("p.result_details").next_element.next_element.next_element)
seoul_starbucks_df = pd.DataFrame(starbucks)
seoul_starbucks_df.head()

seoul_starbucks_df.shape
(634, 6)
seoul_starbucks_df.dtypes
매장명 object
위도 object
경도 object
매장타입 object
주소 object
전화번호 object
dtype: object
seoul_starbucks_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 634 entries, 0 to 633
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 매장명 634 non-null object
1 위도 634 non-null object
2 경도 634 non-null object
3 매장타입 634 non-null object
4 주소 634 non-null object
5 전화번호 634 non-null object
dtypes: object(6)
memory usage: 29.8+ KB
seoul_starbucks_df.to_excel("seoul_starbucks.xlsx", index = False)
서울시 데이터
행정구역 데이터
sgg_df = pd.read_excel("./data/seoul_sgg_list.xlsx")
sgg_df.head()

sgg_df.shape
(25, 4)
인구 데이터
sgg_pop_df = pd.read_csv("./data/report.txt", sep = "\t", header = 2)
sgg_pop_df.head()

sgg_pop_df.shape
(26, 14)
sgg_pop_df["자치구"].unique()
array(['합계', '종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구',
'강북구', '도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구',
'금천구', '영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'],
dtype=object)
sgg_pop_df_selected = sgg_pop_df[sgg_pop_df["자치구"] != "합계"]
sgg_pop_df_selected.head()

sgg_pop_df_selected.info()
<class 'pandas.core.frame.DataFrame'>
Index: 25 entries, 1 to 25
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 기간 25 non-null object
1 자치구 25 non-null object
2 세대 25 non-null object
3 계 25 non-null object
4 남자 25 non-null object
5 여자 25 non-null object
6 계.1 25 non-null object
7 남자.1 25 non-null object
8 여자.1 25 non-null object
9 계.2 25 non-null object
10 남자.2 25 non-null object
11 여자.2 25 non-null object
12 세대당인구 25 non-null float64
13 65세이상고령자 25 non-null object
dtypes: float64(1), object(13)
memory usage: 2.9+ KB
sgg_pop_df_final = sgg_pop_df_selected[["자치구", "계"]]
sgg_pop_df_final.head()

sgg_pop_df_final.columns = ["시군구명", "주민등록인구"]
sgg_pop_df_final.head()
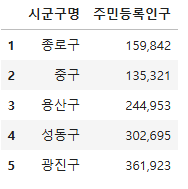
사업체 데이터
sgg_biz_df = pd.read_csv("./data/report2.txt", sep = "\t", header = 2)
sgg_biz_df.head()
- 시군구별 합계만 필요하기 때문에 "동" 컬럼이 "소계" 인 행만 추출
sgg_biz_df_selected = sgg_biz_df[sgg_biz_df["동"] == "소계"]
sgg_biz_df_selected.head()

sgg_biz_df_final = sgg_biz_df_selected[["자치구", "계", "사업체수"]]
sgg_biz_df_final = sgg_biz_df_final.reset_index(drop = True)
sgg_biz_df_final.columns = ["시군구명", "종사자수", "사업체수"]
sgg_biz_df_final.head()
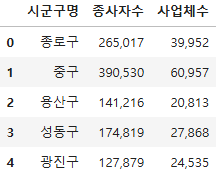
sgg_biz_df_final.to_excel("./data/sgg_biz.xlsx", index = False)
데이터 전처리
seoul_starbucks_df.head()
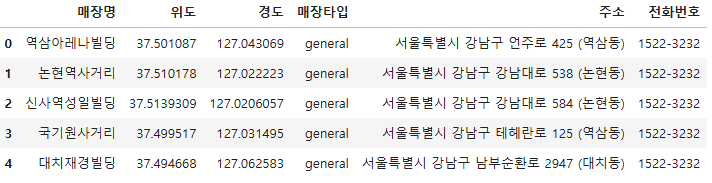
seoul_starbucks_df.loc[0, "주소"].split()[1]
'강남구'
seoul_starbucks_df["주소"].map(lambda x: x.split()[1])
0 강남구
1 강남구
2 강남구
3 강남구
4 강남구
...
629 중랑구
630 중랑구
631 중랑구
632 중랑구
633 중랑구
Name: 주소, Length: 634, dtype: object
seoul_starbucks_df["시군구명"] = seoul_starbucks_df["주소"].str.split().str[1]
seoul_starbucks_df.head()

분석 데이터 생성
sgg_df.head()

시군구별 매장 수 파악
seoul_starbucks_df.head()

starbucks_sgg_count = seoul_starbucks_df.groupby("시군구명")[["매장명"]].count().rename(
columns = {"매장명" : "스타벅스_매장수"}
)
starbucks_sgg_count.head(10)

서울시 시군구 목록 데이터와 스타벅스 매장 수 데이터를 병합
seoul_sgg = pd.merge(sgg_df, starbucks_sgg_count, how = "left", on = "시군구명")
seoul_sgg.head()

서울시 시군구 목록 데이터와 인구통계 데이터를 병합
seoul_sgg = pd.merge(seoul_sgg, sgg_pop_df_final, how = "left", on = "시군구명")
seoul_sgg.head()

서울시 시군구 목록 데이터에 사업체 수 통계 데이터를 병합
seoul_sgg = pd.merge(seoul_sgg, sgg_biz_df_final, how = "left", on = "시군구명")
seoul_sgg.head()

seoul_sgg.to_excel("./data/seoul_sgg_stat.xlsx", index = False)
데이터 시각화
- 앞에서 정리한 데이터 시각화
- 스타벅스 매장 위치를 지도에 시각화
- 스타벅스 매장 분포 확인
- 일반 매장과 리저브, 드라이브스루 매장 분포의 차이 확인
- 시군구 단위로 집계한 별다방 매장수/인구수/사업체수를 시각화
- 스타벅스 매장 위치를 지도에 시각화
지도 시각화
seoul_starbucks_df.head()

starbucks_map = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
starbucks_map

# 스타벅스 매장 위치 서클 마커 그리기
for idx in seoul_starbucks_df.index:
lat = seoul_starbucks_df.loc[idx, "위도"]
lng = seoul_starbucks_df.loc[idx, "경도"]
folium.CircleMarker(
location = [lat, lng],
fill = True,
fill_color = "green",
fill_opacity = 1,
color = "yellow",
weight = 1,
radius = 3
).add_to(starbucks_map)
starbucks_map

- 스타벅스 매장이 대체로 강남권과 중구, 종로구에 많이 분포함
# 스타벅스 매장 타입별 위치 서클 마커 그리기
starbucks_map2 = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
seoul_starbucks_df["매장타입"].unique()
array(['general', 'reserve', 'generalDT', 'generalWT'], dtype=object)
for idx in seoul_starbucks_df.index:
lat = seoul_starbucks_df.loc[idx, "위도"]
lng = seoul_starbucks_df.loc[idx, "경도"]
store_type = seoul_starbucks_df.loc[idx, "매장타입"]
# 매장 타입별 색상 선택을 위한 조건문
if store_type == "general":
fill_color = "gray"
size = 1
elif store_type == "reserve":
fill_color = "blue"
size = 5
elif store_type == "generalDT":
fill_color = "red"
size = 5
elif store_type == "generalWT":
fill_color = "green"
size = 5
folium.CircleMarker(
location = [lat, lng],
fill = True,
fill_color = fill_color,
fill_opacity = 1,
color = fill_color,
weight = 1,
radius = size
).add_to(starbucks_map2)
starbucks_map2

- 드라이브스루(빨간색) 매장들은 주로 서울 외곽에 위치해 있음
- 리저브(파란색), 워킹스루(초록색)은 주로 서울 중심지에 분포
시군구별 매장 수 시각화
seoul_sgg.head()

seoul_sgg_geo = json.load(open("./data/seoul_sgg.geojson", encoding = "utf-8"))
seoul_sgg_geo["features"][0]["properties"]
{'SIG_CD': '11320',
'SIG_KOR_NM': '도봉구',
'SIG_ENG_NM': 'Dobong-gu',
'ESRI_PK': 0,
'SHAPE_AREA': 0.00210990544544,
'SHAPE_LEN': 0.239901251347}
starbucks_bubble = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
# 서울시 시군구 경계 지도 그리기
def style_function(feature):
return {
"opacity" : 0.7,
"weight" : 1,
"color" : "white",
"fillOpacity" : 0,
"dashArray" : "5, 5"
}
folium.GeoJson(
seoul_sgg_geo,
style_function = style_function
).add_to(starbucks_bubble)
<folium.features.GeoJson at 0x1e1d0595220>
starbucks_bubble

# 서울시 시군구 평균 스타벅스 매장 수 계산
# 평균값보다 많은 스타벅스 매장이 있는 곳은 다르게 표현
starbucks_mean = seoul_sgg["스타벅스_매장수"].mean()
starbucks_mean
25.36
for idx in seoul_sgg.index:
lat = seoul_sgg.loc[idx, "위도"]
lng = seoul_sgg.loc[idx, "경도"]
count = seoul_sgg.loc[idx, "스타벅스_매장수"]
if count > starbucks_mean:
fill_color = "red"
else:
fill_color = "blue"
folium.CircleMarker(
location = [lat, lng],
fill_color = fill_color,
fill_opacity = 0.7,
color = "#FFFF00",
weight = 1.5,
radius = count/2
).add_to(starbucks_bubble)
starbucks_bubble

서울 시군구별 별다방 매장 수를 단계구분도로 시각화
starbucks_choropleth = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
folium.Choropleth(
geo_data = seoul_sgg_geo,
data = seoul_sgg,
columns = ["시군구명", "스타벅스_매장수"],
fill_color = "YlGn",
fill_opacity = 0.7,
line_opacity = 0.5,
key_on = "properties.SIG_KOR_NM"
).add_to(starbucks_choropleth)
<folium.features.Choropleth at 0x1e1d05978f0>starbucks_choropleth

별다방 매장 수와 인구 수 비교
- 가설 : 거주 인구가 많은 지역에 스타벅스 매장이 많이 입지해 있을 것이다
seoul_sgg.head()

seoul_sgg.dtypes
시군구코드 int64
시군구명 object
위도 float64
경도 float64
스타벅스_매장수 int64
주민등록인구 object
종사자수 object
사업체수 object
dtype: object
# 주민등록인구 전처리
seoul_sgg["주민등록인구"] = seoul_sgg["주민등록인구"].str.replace(",", "").astype(int)
seoul_sgg.head()
seoul_sgg.dtypes
시군구코드 int64
시군구명 object
위도 float64
경도 float64
스타벅스_매장수 int64
주민등록인구 int32
종사자수 object
사업체수 object
dtype: objectstarbucks_choropleth = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
folium.Choropleth(
geo_data = seoul_sgg_geo,
data = seoul_sgg,
columns = ["시군구명", "주민등록인구"],
fill_color = "YlGn",
fill_opacity = 0.7,
line_opacity = 0.5,
key_on = "properties.SIG_KOR_NM"
).add_to(starbucks_choropleth)
<folium.features.Choropleth at 0x1e1d117c890>
starbucks_choropleth

- 시군구별 주민등록인구수와 스타벅스 매장 수는 확연히 차이가 있음
- 주민등록인구수 : 송파구, 강서구, 관악구, 노원구가 높음
인구 만 명당 별다방 매장 수 컬럼 추가
- 시각적으로 확인한 내용을 수치적으로 추가 확인
seoul_sgg["만명당_매장수"] = seoul_sgg["스타벅스_매장수"] / (seoul_sgg["주민등록인구"] / 10000)
seoul_sgg.head()
viz_map1 = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
folium.GeoJson(
seoul_sgg_geo,
style_function = style_function
).add_to(viz_map1)
# 만 명당 매장 수 기준 상위 10% 추출 값
top = seoul_sgg["만명당_매장수"].quantile(0.9)
top
1.5220545466038038
for idx in seoul_sgg.index:
lat = seoul_sgg.loc[idx, "위도"]
lng = seoul_sgg.loc[idx, "경도"]
r = seoul_sgg.loc[idx, "만명당_매장수"]
if r > top:
fill_color = "#FF3300"
else:
fill_color = "#CCFF33"
folium.CircleMarker(
location = [lat, lng],
fill_color = fill_color,
fill_opacity = 0.7,
color = "#FFFF00",
weight = 1.5,
radius = r * 10
).add_to(viz_map1)
viz_map1

- 인구 단계구분도에서 인구가 적은 지역으로 표시되었던 중구와 종로구가 1만명당 매장 수가 가장 많은 것으로 표시됨
- 주민등록인구와 스타벅스 매장 수는 서로 비례하지 않음
- 가설 "거주 인구가 많은 지역에 스타벅스 매장이 많이 입지해 있을 것이다" 는 틀렸음
스타벅스 매장 수와 사업체 수 비교
- 가설 : 직장인이 많은 지역에 스타벅스 매장이 많이 입지해 있을 것이다
- 가설 검증을 위해 스타벅스 매장 수와 사업체 종사자 수 사이의 관계 분석
seoul_sgg.head()

seoul_sgg["종사자수"] = seoul_sgg["종사자수"].str.replace(",", "").astype(int)
# 종사자 1만명당 스타벅스 매장 수
seoul_sgg["종사자수_만명당_매장수"] = seoul_sgg["스타벅스_매장수"] / (seoul_sgg["종사자수"] / 10000)
seoul_sgg.head()

viz_map2 = folium.Map(
location = [37.55, 126.98],
tiles = "Cartodb dark_matter",
zoom_start = 11
)
folium.GeoJson(
seoul_sgg_geo,
style_function = style_function
).add_to(viz_map2)
# 종사자수 만 명당 매장 수 기준 상위 10% 추출 값
top = seoul_sgg["종사자수_만명당_매장수"].quantile(0.9)
top
1.6906625790253358
for idx in seoul_sgg.index:
lat = seoul_sgg.loc[idx, "위도"]
lng = seoul_sgg.loc[idx, "경도"]
r = seoul_sgg.loc[idx, "종사자수_만명당_매장수"]
if r > top:
fill_color = "#FF3300"
else:
fill_color = "#CCFF33"
folium.CircleMarker(
location = [lat, lng],
fill_color = fill_color,
fill_opacity = 0.7,
color = "#FFFF00",
weight = 1.5,
radius = r * 10
).add_to(viz_map2)
viz_map2

seoul_sgg.sort_values("종사자수_만명당_매장수", ascending = False).head()

- 상위 3개 지역은 서대문구, 은평구, 용산구
- 상위 3개 지역과 다른 지역의 원 크기가 크게 차이 나지는 않음
- 사업체 종사자 수와 스타벅스 매장 수는 대체로 비례하는 경향이 있음
통계 검정
seoul_sgg[["스타벅스_매장수", "주민등록인구", "종사자수"]].corr()

stats.pearsonr(seoul_sgg["스타벅스_매장수"], seoul_sgg["종사자수"])
PearsonRResult(statistic=0.9514251645853266, pvalue=2.944134184975513e-13)'07_Data_Analysis' 카테고리의 다른 글
| 21_청소기 가성비 데이터 수집&분석 (1) | 2025.03.25 |
|---|---|
| 19_Wordcloud, Polium_제주도 맛집 데이터 (6) | 2025.03.20 |
| 18_외국인 관광객 데이터 분석 (0) | 2025.03.20 |
| 17_유투브 랭킹 데이터 분석 (0) | 2025.03.19 |
| 16_기온 데이터 분석 (0) | 2025.03.19 |