728x90
로이터뉴스_카테고리분류
from tensorflow import keras
from tensorflow.keras.datasets import reuters
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = reuters.load_data()
x_train.shape, x_test.shape
((8982,), (2246,))
np.unique(y_train, return_counts = True)
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype=int64),
array([ 55, 432, 74, 3159, 1949, 17, 48, 16, 139, 101, 124,
390, 49, 172, 26, 20, 444, 39, 66, 549, 269, 100,
15, 41, 62, 92, 24, 15, 48, 19, 45, 39, 32,
11, 50, 10, 49, 19, 19, 24, 36, 30, 13, 21,
12, 18], dtype=int64))
- 로이터 뉴스 카테고리 분류 데이터
- 총 11258개의 뉴스 기사 데이터
- 총 46개의 카테고리 분류
- 예)
- 중부 지방은 대체로 맑겠으나, 남부 지방은 구름이 많겠습니다 -> 날씨
- 올 초부터 유동성의 힘으로 주가가 일정하게 상승했습니다 -> 주식
word_index = reuters.get_word_index()
word_index
{'mdbl': 10996,
'fawc': 16260,
'degussa': 12089,
'woods': 8803,
'hanging': 13796,
...
idx2word = {0 : "<PAD>", 1 : "<s>", 2 : "<UNK>"}
idx2word.update({value + 3 : key for key, value in word_index.items()})
print(x_train[0])
[1, 27595, 28842, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 4579, 1005, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 1245, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]
" ".join(map(lambda x: idx2word[x], x_train[0]))
'<s> mcgrath rentcorp said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3'
len(word_index.keys())
30979
사용할 단어 수 테스트
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words = 1000)
# 단어 수를 1000개정도 써도 문장을 이해하는데 문제가 없음
idx2word = {0 : "<PAD>", 1 : "<s>", 2 : "<UNK>"}
idx2word.update({value + 3 : key for key, value in word_index.items()})
" ".join(map(lambda x: idx2word[x], x_train[0]))
'<s> <UNK> <UNK> said as a result of its december acquisition of <UNK> co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and <UNK> <UNK> revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash <UNK> per share this year should be 2 50 to three dlrs reuter 3'
문장의 길이 분석
lengths = np.array([len(x) for x in x_train])
plt.figure()
plt.hist(lengths, bins=20)
plt.xlabel("lengths")
plt.ylabel("frequency")
plt.show()

np.mean(lengths), np.min(lengths), np.max(lengths)
(145.5398574927633, 13, 2376)
np.quantile(lengths, [0.25, 0.5, 0.75])
array([ 60., 95., 179.])
# 종속변수 종류 수 확인
len(np.unique(y_train))
46
데이터 분할
# 딥러닝에서는 test데이터를 훈련에 사용하면 일반화 성능을 제대로 파악할 수 없어서(에포크를 여러번 돌리므로)
# train데이터를 따로 분할하여 훈련
x_sub, x_val, y_sub, y_val = train_test_split(x_train, y_train, test_size = 0.2,
stratify = y_train, random_state = 26)
x_sub.shape, x_val.shape, x_test.shape
((7185,), (1797,), (2246,))
# truncating = "post" : 뉴스 기사는 중요한 정보가 앞부분에 있을 가능성이 높으므로
sub_seq = pad_sequences(x_sub, maxlen = 150, truncating = "post")
val_seq = pad_sequences(x_val, maxlen = 150, truncating = "post")
test_seq = pad_sequences(x_test, maxlen =150, truncating = "post")
모델 설계
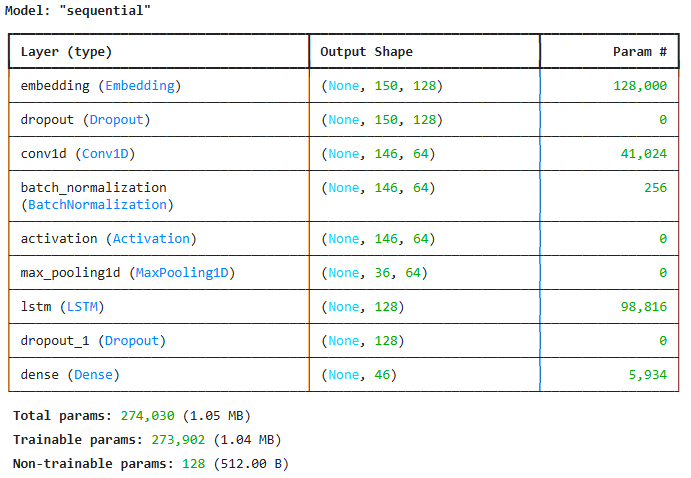
model = keras.Sequential()
model.add(keras.Input(shape = (150,)))
model.add(keras.layers.Embedding(1000, 128))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Conv1D(64, 5))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation(keras.activations.relu))
model.add(keras.layers.MaxPool1D(4))
model.add(keras.layers.LSTM(128, dropout = 0.2))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(46, activation = "softmax"))
model.compile(optimizer = "adam", loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
es_cb = keras.callbacks.EarlyStopping(patience = 4, restore_best_weights = True)
model.summary()
histroy = model.fit(sub_seq, y_sub, epochs = 100, batch_size = 32,
validation_data = (val_seq, y_val), callbacks = [es_cb])

model.evaluate(test_seq, y_test)

[0.8792003393173218, 0.7960819005966187]728x90
'09_DL(Deep_Learning)' 카테고리의 다른 글
| konlpy설치방법(한국어 형태소 분석기) (1) | 2025.04.30 |
|---|---|
| 17_RNN과 CNN 조합 (0) | 2025.04.29 |
| 15_LSTM&GRU (0) | 2025.04.29 |
| 14_순환신경망(텍스트 분류)-IMDB리뷰_데이터셋 (4) | 2025.04.28 |
| 13_순환 신경망(RNN) (1) | 2025.04.28 |