728x90
LSTM&GRU
# simple RNN 을 쓰는 경우는 거의 없고 보통 LSTM이나 GRU를 씀
LSTM(Long Short-Term Memory)구조

- 단기 기억을 오래 기억하기 위해 고안되었음

# cell state: 장기기억
# 삭제|입력|출력 게이트
- 은닉 상태를 만드는 방법
- output gate layer(출력 게이트)
- 입력과 이전 타임스텝의 은닉 상태를 가중치에 곱한 후 활성화 함수를 통과시켜 다음 은닉 상태를 만듦
- 이 때 기본 순환층과는 달리 시그모이드 활성화 함수를 사용
- tanh 활성화 함수를 통과한 값과 곱해져서 은닉 상태를 만듦
- 입력과 이전 타임스텝의 은닉 상태를 가중치에 곱한 후 활성화 함수를 통과시켜 다음 은닉 상태를 만듦
- output gate layer(출력 게이트)
- LSTM은 순환되는 상태가 2개
- 은닉 상태
- 셀 상태(cell state)
- 다음 층으로 전달되지 않고 LSTM셀에서 순환만 되는 값
- 셀 상태를 계산하는 과정
- forget gate layer(삭제 게이트)
- 정보를 제거하는 역할
- 입력과 은닉 상태를 또 다른 가중치에 곱한 다음 시그모이드 함수를 통과
- 이전 타임스텝의 셀 상태와 곱하여 새로운 셀 상태를 만듦
- 이 셀 상태가 오른쪽에서 tanh 함수를 통과하여 새로운 은닉 상태를 만드는 데 기여
- input gate layer(입력 게이트)
- 새로운 정보를 셀 상태에 추가
- 입력과 은닉 상태를 각기 다른 가중치에 곱함
- 하나는 시그모이드 함수, 하나는 tanh함수를 통과
- 두 결과를 곱함
- 이전 셀 상태와 더함
- forget gate layer(삭제 게이트)
데이터 준비
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow import keras
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 데이터 로드
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 500)
# 훈련 세트와 검증 세트로 나누기
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2,
stratify = y_train, random_state = 26)
# 패딩(컬럼 개수를 맞추기 위해 글자수를 100개로 제한)
train_seq = pad_sequences(x_train, maxlen = 100)
val_seq = pad_sequences(x_val, maxlen = 100)
# LSTM 모델 생성
model = keras.Sequential()
model.add(keras.Input(shape = (100,)))
model.add(keras.layers.Embedding(500, 128))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1, activation = "sigmoid"))
model.summary()

- LSTM 셀 파라미터 개수
- ((128 * 8)) + (8 * 8) + 8) * 4 = 4384) (원래는 tanh뿐이었으나,σ,σ,tanh,σ 4개)
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model.compile(optimizer = rmsprop, loss = "binary_crossentropy", metrics = ["accuracy"])
cp_cb = keras.callbacks.ModelCheckpoint("./model/best-lstm-model.keras", save_best_only = True)
es_cb = keras.callbacks.EarlyStopping(patience = 4, restore_best_weights = True)
history = model.fit(train_seq, y_train, epochs = 100, batch_size = 64,
validation_data = (val_seq, y_val), callbacks = [cp_cb, es_cb])

...
plt.figure()
plt.plot(history.history["loss"], label = "train_loss")
plt.plot(history.history["val_loss"], label = "val_loss")
plt.plot(history.history["accuracy"], label = "train_acc")
plt.plot(history.history["val_accuracy"], label = "val_acc")
plt.xlabel("epoch")
plt.legend()
plt.show()

순환층에 드롭아웃 적용
- 순환층은 자체적으로 드롭아웃 기능을 제공
- SimpleRNN과 LSTM 클래스 모두 dropout 매개변수와 recurrent_dropout 매개변수를 가지고 있음
- dropout : 셀의 입력에 드롭아웃을 적용
- recurrent_dropout : 순환되는 은닉 상태에 드롭아웃을 적용
- 버전에 따라 recurrent_dropout이 GPU를 사용하지 못하는 경우가 있음
- SimpleRNN과 LSTM 클래스 모두 dropout 매개변수와 recurrent_dropout 매개변수를 가지고 있음
model2 = keras.Sequential()
model2.add(keras.Input(shape = (100,)))
model2.add(keras.layers.Embedding(500, 128))
model2.add(keras.layers.LSTM(8, dropout = 0.3))
model2.add(keras.layers.Dense(1, activation = "sigmoid"))
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model2.compile(optimizer = rmsprop, loss = "binary_crossentropy", metrics = ["accuracy"])
cp_cb = keras.callbacks.ModelCheckpoint("./model/best-dropout-model.keras", save_best_only = True)
es_cb = keras.callbacks.EarlyStopping(patience = 4, restore_best_weights = True)
history = model2.fit(train_seq, y_train, epochs = 100, batch_size = 64,
validation_data = (val_seq, y_val), callbacks = [cp_cb, es_cb])

...
plt.figure()
plt.plot(history.history["loss"], label = "train_loss")
plt.plot(history.history["val_loss"], label = "val_loss")
plt.plot(history.history["accuracy"], label = "train_acc")
plt.plot(history.history["val_accuracy"], label = "val_acc")
plt.xlabel("epoch")
plt.legend()
plt.show()

2개의 층을 연결
- 순환층을 연결할 때의 주의점
- 순환층의 은닉 상태는 샘플의 마지막 타임스텝에 대한 은닉 상태만 다음 층으로 전달
- 순환층을 쌓게 되면 모든 순환층에 순차 데이터가 필요함
- 앞쪽의 순환층이 모든 타임스텝에 대한 은닉 상태를 출력해야함
- return_sequences = True 로 지정
- 순환층의 은닉 상태는 샘플의 마지막 타임스텝에 대한 은닉 상태만 다음 층으로 전달
model3 = keras.Sequential()
model3.add(keras.Input(shape = (100,)))
model3.add(keras.layers.Embedding(500, 128))
model3.add(keras.layers.LSTM(8, dropout = 0.3, return_sequences = True))
model3.add(keras.layers.LSTM(8, dropout = 0.3))
model3.add(keras.layers.Dense(1, activation = "sigmoid"))
model3.summary()

- 첫 번째 LSTM
- 모든 타임스텝(100개)의 은닉 상태를 출력하기 때문에 출력의 크기가 (None, 100, 8)
- 파라미터의 수 : ((128 * 8) + (8 * 8) + 8) * 4 = 4384
- 두 번째 LSTM
- 마지막 타임스텝의 은닉 상태만 출력하기 때문에 출력의 크기가 (None, 8)
- 파라미터의 수 : ((8 * 8) + (8 * 8) + 8) * 4 = 544
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model3.compile(optimizer = rmsprop, loss = "binary_crossentropy", metrics = ["accuracy"])
cp_cb = keras.callbacks.ModelCheckpoint("./model/best-2rnn-model.keras", save_best_only = True)
es_cb = keras.callbacks.EarlyStopping(patience = 4, restore_best_weights = True)
history = model3.fit(train_seq, y_train, epochs = 100, batch_size = 64,
validation_data = (val_seq, y_val), callbacks = [cp_cb, es_cb])

...
plt.figure()
plt.plot(history.history["loss"], label = "train_loss")
plt.plot(history.history["val_loss"], label = "val_loss")
plt.plot(history.history["accuracy"], label = "train_acc")
plt.plot(history.history["val_accuracy"], label = "val_acc")
plt.xlabel("epoch")
plt.legend()
plt.show()

GRU(Grated Recurrent Unit) 구조

# GRU 만드신 조경현교수님
# LSTM에 비해 GRU는 4 -> 3 으로 간소화
- LSTM 을 간소화한 버전
- LSTM처럼 셀 상태를 계산하지 않고 은닉 상태 하나만 포함
- LSTM보다 가중치가 적기 때문에 계산량이 적지만 성능은 LSTM과 유사함
- 데이터 양이 적을 때는 GRU의 성능이 더 좋고 데이터 양이 많을 때는 LSTM의 성능이 더 좋아지는 경향이 있음
- GRU와 LSTM중 어떤 것이 더 낫다라고 말할 수는 없음
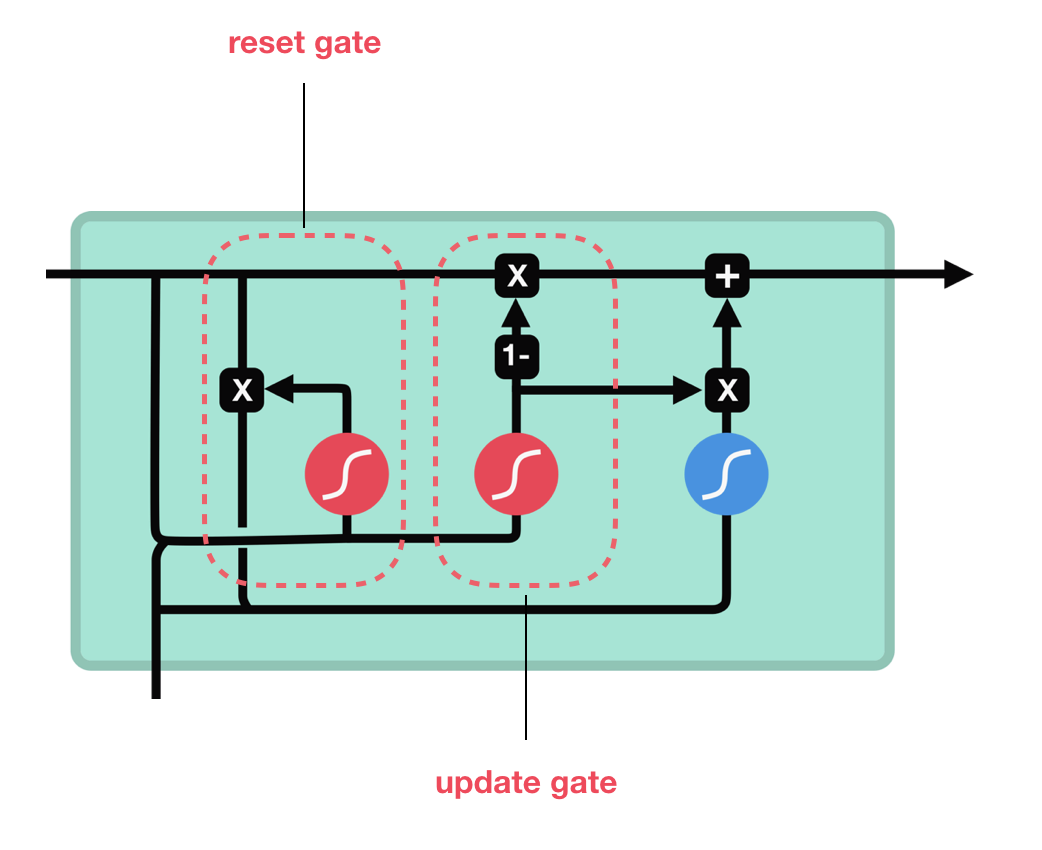
- GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀 3개가 들어 있음
- 2개는 시그모이드 활성화 함수를 사용하고 하나는 tanh 활성화 함수를 사용
- reset_gate
- 셀의 출력이 은닉 상태에 바로 곱해져 삭제 게이트 역할을 수행
- update_gate
- 어떤 정보를 얼마만큼 유지하고 어떤 정보를 추가할지 결정하는 역할
model4 = keras.Sequential()
model4.add(keras.Input(shape = (100,)))
model4.add(keras.layers.Embedding(500, 128))
model4.add(keras.layers.GRU(8, dropout = 0.3))
model4.add(keras.layers.Dense(1, activation = "sigmoid"))
model4.summary()

((128 * 8) + (8 * 8) + 8 + 8) * 3
# (유닛의 편향(8) 추가)의 파라미터수
3312
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model4.compile(optimizer = rmsprop, loss = "binary_crossentropy", metrics = ["accuracy"])
cp_cb = keras.callbacks.ModelCheckpoint("./model/best-gru-model.keras", save_best_only = True)
es_cb = keras.callbacks.EarlyStopping(patience = 4, restore_best_weights = True)
history = model4.fit(train_seq, y_train, epochs = 100, batch_size = 64,
validation_data = (val_seq, y_val), callbacks = [cp_cb, es_cb])

...
plt.figure()
plt.plot(history.history["loss"], label = "train_loss")
plt.plot(history.history["val_loss"], label = "val_loss")
plt.plot(history.history["accuracy"], label = "train_acc")
plt.plot(history.history["val_accuracy"], label = "val_acc")
plt.xlabel("epoch")
plt.legend()
plt.show()

best model 검증
test_seq = pad_sequences(x_test, maxlen = 100)
rnn_model = keras.models.load_model("./model/best-2rnn-model.keras")
rnn_model.evaluate(test_seq, y_test)

[0.42045316100120544, 0.8050400018692017]728x90
'09_DL(Deep_Learning)' 카테고리의 다른 글
| 17_RNN과 CNN 조합 (0) | 2025.04.29 |
|---|---|
| 16_로이터뉴스_카테고리분류 (3) | 2025.04.29 |
| 14_순환신경망(텍스트 분류)-IMDB리뷰_데이터셋 (4) | 2025.04.28 |
| 13_순환 신경망(RNN) (1) | 2025.04.28 |
| 12_CIFAR10 (0) | 2025.04.28 |