728x90
초음파 광물 예측
초음파 광물 예측 데이터
- 1988년 존스홉킨스 대학교의 세즈노프스키 교수가 1986년 힌튼 교수가 발표한 역전파 알고리즘에 관심을 갖고 은닉층과 역전파의 효과를 실험하기 위해 정리한 데이터
- 광석과 일반 돌에 각각 음파 탐지기를 쏜 후 그 결과를 정리
import pandas as pd
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
import missingno as msno
import matplotlib.pyplot as plt
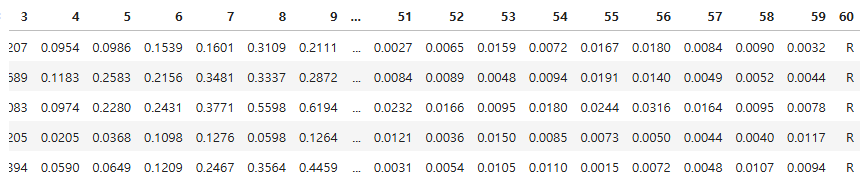
df = pd.read_csv("./data/sonar.csv", header = None)
df.head()
df.shape
(208, 61)
df.describe()

df.isna().sum()
0 0
1 0
2 0
3 0
4 0
..
56 0
57 0
58 0
59 0
60 0
Length: 61, dtype: int64
# 컬럼이 너무 많아서 결측치 확인이 힘듦
# pip install missingno
# 결측치 유무 확인
msno.matrix(df)

df[60].value_counts()
60
M 111
R 97
Name: count, dtype: int64
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
ver1(원핫인코딩 방식)
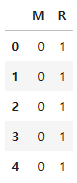
enc_y = pd.get_dummies(y, dtype = int)
enc_y.head()
# 데이터 분할
x_train, x_test, y_train, y_test = train_test_split(x, enc_y, test_size = 0.2, stratify = enc_y, random_state = 26)
x_sub, x_val, y_sub, y_val = train_test_split(x_train, y_train, test_size = 0.2, stratify = y_train, random_state = 26)
x_sub.shape, x_val.shape, x_test.shape
((132, 60), (34, 60), (42, 60))
# 스케일링
mm = MinMaxScaler()
scaled_sub = mm.fit_transform(x_sub)
scaled_val = mm.transform(x_val)
scaled_test = mm.transform(x_test)
# 모델링
model = keras.Sequential()
model.add(keras.Input(shape = (60,))) # 입력층
model.add(keras.layers.Dense(64, activation = "relu")) # 은닉층
model.add(keras.layers.Dense(32, activation = "relu"))
model.add(keras.layers.Dense(2, activation = "softmax")) # 출력층
model.summary()

model.compile(loss = "categorical_crossentropy", optimizer = "adam", metrics = ["accuracy"])
es_cb = keras.callbacks.EarlyStopping(patience = 8, restore_best_weights = True)
model.fit(scaled_sub, y_sub, epochs = 200, batch_size=16, validation_data=(x_val, y_val),
callbacks=[es_cb])
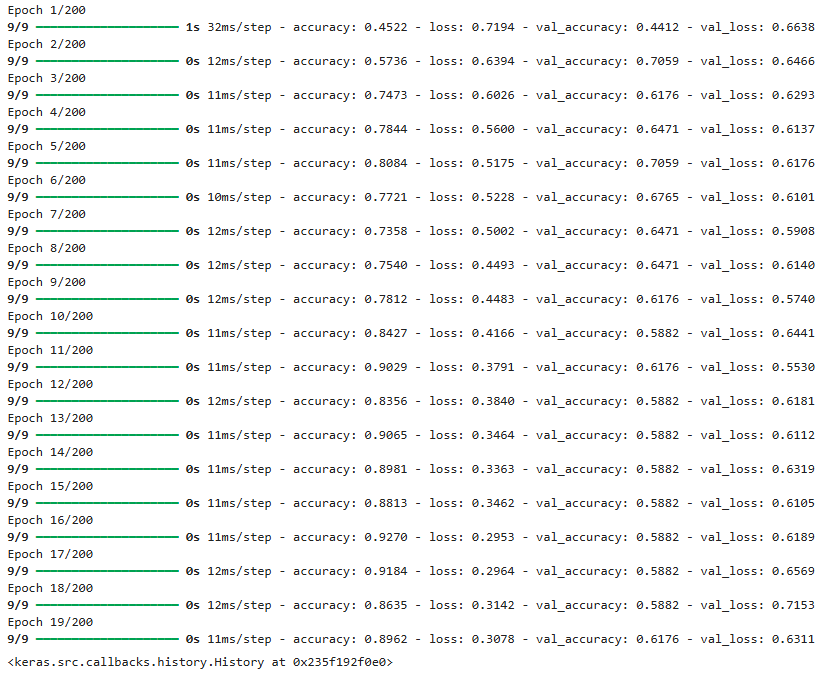
model.evaluate(scaled_test, y_test)

[0.45047587156295776, 0.6904761791229248]
ver2(LableEncoder)
le = LabelEncoder()
y = le.fit_transform(y)
y
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, stratify = y,
random_state = 26)
x_sub, x_val, y_sub, y_val = train_test_split(x_train, y_train, test_size = 0.2, stratify = y_train,
random_state = 26)
mm = MinMaxScaler()
scaled_sub = mm.fit_transform(x_sub)
scaled_val = mm.transform(x_val)
scaled_test = mm.transform(x_test)
model2 = keras.Sequential()
model2.add(keras.Input(shape=(60,)))
model2.add(keras.layers.Dense(64, activation = "relu"))
model2.add(keras.layers.Dense(32, activation = "relu"))
model2.add(keras.layers.Dense(1, activation = "sigmoid")) # 이진분류이므로 sigmoid선호
model2.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy"])
es_cb = keras.callbacks.EarlyStopping(patience = 8, restore_best_weights = True)
model2.fit(scaled_sub, y_sub, epochs = 200, batch_size = 16, validation_data = (scaled_val, y_val),
callbacks = [es_cb])

...
model2.evaluate(scaled_test, y_test)

[0.4113645553588867, 0.8333333134651184]
model2.predict(scaled_test[:5])

array([[0.52603143],
[0.9594594 ],
[0.995561 ],
[0.7798952 ],
[0.4923146 ]], dtype=float32)
y_test[:5]
array([0, 1, 1, 1, 0])728x90
'09_DL(Deep_Learning)' 카테고리의 다른 글
| 08_합성곱 신경망_구성요소 (0) | 2025.04.24 |
|---|---|
| 07_보스턴 집값 예측 (0) | 2025.04.24 |
| 05_다중분류(Iris) (0) | 2025.04.23 |
| 04_신경망 모델 훈련 도구 (1) | 2025.04.23 |
| 월별 사인(sin) 코사인(cos) 시각화 (0) | 2025.04.21 |