728x90
서울교통공사 에스컬레이터 설치 정보 전처리 및 csv로 저장
(1~8호선 정보 + 9호선 정보)
import pandas as pd
01. 1~8호선 정보

...

# 첫 1행과 마지막 1행을 제외하고 엑셀파일을 읽어들임
df = pd.read_excel("./data/서울교통공사_에스컬레이터 설치 정보(1-8호선).xlsx", header = 1, skipfooter = 1)
df.head()
df.tail()

df.columns
Index(['연번\n(총괄정렬용)', '연번', '호선', '역명', '호기', '승강기번호', '설치위치', '운행구간(자체조사)',
'운행방향'],
dtype='object')
# 호선 -> 노선명
df.columns = ['연번\n(총괄정렬용)', '연번', '노선명', '역명', '호기', '승강기번호', '설치위치', '운행구간(자체조사)',
'운행방향']
df.dtypes
연번\n(총괄정렬용) float64
연번 int64
노선명 object
역명 object
호기 int64
승강기번호 object
설치위치 object
운행구간(자체조사) object
운행방향 object
dtype: object
# 데이터 타입을 확인
type(df.iloc[0, 0])
numpy.float64
# string타입으로 변경
df["노선명"] = df["노선명"].astype(str)
# (연)을 모두 삭제
df["노선명"] = df["노선명"].str.replace("(연)", "")
df["노선명"].unique()
array(['1', '2', '3', '4', '5', '6', '7', '8'], dtype=object)
# 호선명 뒤에 "호선" 붙이기
df["노선명"] = df["노선명"] + "호선"
df.columns = ['연번\n(총괄정렬용)', '연번', '노선명', '역명', '호기', '승강기번호', '설치위치', '운행구간(자체조사)',
'운행방향']
# 불필요한 컬럼 삭제
df = df.drop(columns=["연번\n(총괄정렬용)", "연번", "승강기번호", "설치위치", "운행구간(자체조사)", "운행방향"])
df.head()

df.tail()

# 역명 뒤의 (숫자) 삭제
for i in range(1, 10):
df["역명"] = df["역명"].str.replace(f'({i})', '')
df.head()

df["노선명"].unique()
array(['1호선', '2호선', '3호선', '4호선', '5호선', '6호선', '7호선', '8호선'],
dtype=object)
df["노선명"].str.replace("(연)", "")
0 1호선
1 1호선
2 1호선
3 1호선
4 1호선
...
1866 8호선
1867 8호선
1868 8호선
1869 8호선
1870 8호선
Name: 노선명, Length: 1871, dtype: object
# 노선명 8호선 뒤의 (연) 삭제
df["노선명"] = df["노선명"].str.replace("(연)", "")
df.head()
df["역명"].unique()
array(['서울역', '시청', '종각', '종로3가', '동대문', '동묘앞', '제기동', '청량리', '을지로입구',
'을지로4가', '동대문역사문화공원', '신당', '상왕십리', '왕십리', '한양대', '뚝섬', '성수', '용두',
'건대입구', '구의', '강변', '잠실나루', '잠실', '잠실새내', '종합운동장', '삼성', '선릉',
'역삼', '교대', '서초', '방배', '사당', '낙성대', '서울대입구', '봉천', '신림', '신대방',
'구로디지털단지', '대림', '신도림', '양천구청', '신정네거리', '문래', '영등포구청', '당산', '합정',
'홍대입구', '신촌', '이대', '아현', '충정로', '구파발', '연신내', '불광', '녹번', '독립문',
'경복궁', '안국', '을지로3가', '동대입구', '약수', '금호', '옥수', '압구정', '신사',
'고속터미널', '남부터미널', '양재', '매봉', '도곡', '대치', '학여울', '대청', '일원', '수서',
'가락시장', '경찰병원', '오금', '당고개', '상계', '노원', '창동', '쌍문', '수유', '미아',
'미아사거리', '길음', '성신여대입구', '한성대입구', '혜화', '충무로', '명동', '회현', '삼각지',
'신용산', '이촌', '총신대입구', '남태령', '방화', '김포공항', '송정', '마곡', '우장산', '화곡',
'까치산', '신정', '목동', '오목교', '양평', '영등포시장', '신길', '여의도', '여의나루', '마포',
'공덕', '애오개', '서대문', '광화문', '신금호', '행당', '마장', '답십리', '장한평', '군자',
'아차산', '광나루', '천호', '강동', '길동', '굽은다리', '명일', '고덕', '상일동', '둔촌동',
'올림픽공원', '방이', '개롱', '거여', '마천', '강일', '미사', '하남풍산', '하남시청',
'하남검단산', '응암', '역촌', '독바위', '구산', '새절', '증산', '디지털미디어시티', '월드컵경기장',
'마포구청', '망원', '상수', '광흥창', '대흥', '효창공원앞', '녹사평', '이태원', '한강진',
'버티고개', '청구', '창신', '보문', '안암', '고려대', '월곡', '상월곡', '돌곶이', '석계',
'태릉입구', '화랑대', '봉화산', '신내', '수락산', '마들', '중계', '하계', '공릉', '먹골',
'중화', '상봉', '면목', '사가정', '용마산', '중곡', '어린이대공원', '자양', '청담', '강남구청',
'학동', '논현', '반포', '내방', '이수', '남성', '숭실대입구', '상도', '장승배기',
'신대방삼거리', '보라매', '신풍', '남구로', '가산디지털단지', '철산', '광명사거리', '천왕', '온수',
'암사역사공원', '암사', '강동구청', '몽촌토성', '송파', '문정', '장지', '복정', '남위례',
'산성', '남한산성입구', '단대오거리', '모란'], dtype=object)
df.head()

ndf = df.groupby(["노선명", "역명"])[["호기"]].max()
# 컬럼명 변경
ndf = ndf.rename(columns={"호기" : "에스컬레이터 대수"})
# 인덱스 초기화
ndf = ndf.reset_index()
ndf

# csv파일로 저장(인덱스는 저장안함, 한글 글자깨짐 안되게) - 1~8호선 정보만 임시저장
ndf.to_csv("escalator_cnt.csv", index=False, encoding="utf-8-sig")

02. 9호선 정보

df9 = pd.read_excel("./data/9호선 편의시설 개수 정보_v2.xlsx")
df9.head()

# 특정 컬럼만 추출
df9 = df9[["노선명","역명","에스컬레이터"]]
df9.head()
# 정보를 합치기 위해 컬럼명을 일치시킴
df9 = df9.rename(columns = {"에스컬레이터":"에스컬레이터 대수"})
# 정보 합치기(1~8호선 + 9호선)
escalator_count = pd.concat([ndf,df9],axis=0,ignore_index=True)
escalator_count
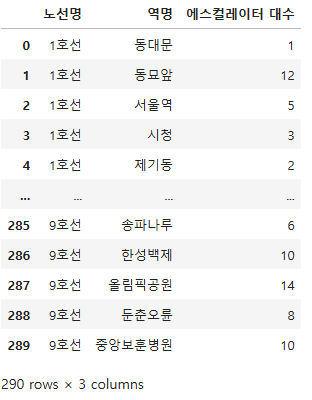
# csv파일로 저장(인덱스는 저장안함, 한글 글자깨짐 안되게)
escalator_count.to_csv("./result_files/escalator_cnt_include9.csv", index=False, encoding="utf-8-sig")
'05_Pandas' 카테고리의 다른 글
| 현금영수증 내역 연도별로 합치기(국세청 홈텍스) (1) | 2025.05.06 |
|---|---|
| [Pandas]datetime에서 시간만 추출 (0) | 2025.04.17 |
| 06_서울교통공사_역사면적정보 (0) | 2025.03.27 |
| 05-5_연습문제_occupation (0) | 2025.03.07 |
| 05-4_연습문제_Vaccine (0) | 2025.03.07 |