09_DL(Deep_Learning)
03_다층 인공신경망
chuuvelop
2025. 4. 18. 17:52
728x90
다층 인공신경망
from tensorflow import keras
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
데이터 전처리
- 픽셀값을 0 ~ 1 사이로 스케일링
- 2차원 배열을 1차원 배열로 변환
- 훈련, 검증 나누기
scaled_train = x_train / 255
scaled_train = scaled_train.reshape(-1, 28 * 28)
scaled_train.shape
(60000, 784)
scaled_train, scaled_val, y_train, y_val = train_test_split(scaled_train, y_train, test_size = 0.2,
stratify = y_train, random_state = 26)
scaled_train.shape, scaled_val.shape
((48000, 784), (12000, 784))
심층신경망 구성
- 인공 신경망에 층을 추가한 구조

- 단층 신경망과의 차이는 입력층과 출력층 사이에 밀집층이 추가된 것
- 입력층과 출력층 사이에 있는 모든 층을 은닉층(hidden layer)라고 부름

- 활성화 함수(activation function)
- 활성화 함수를 쓰는 이유
- 예) a * 4 + 2 = b
- b * 3 - 5 = c
- 위 2개의 식은 a * 12 + 1 = c 로 단순화가 가능
- 은닉층이 선형적인 산술계산만 한다면 층이 깊어지더라도 계산식이 단순화되어 학습 효율이 떨어짐
- 따라서 활성화함수로 선형계산을 비선형 계산으로 비틀어주는 과정이 필요
- 활성화 함수를 쓰는 이유
- 출력층에 적용하는 활성화 함수와 은닉층에 적용하는 활성화 함수는 차이가 있음
- 출력층의 활성화 함수
- 출력층 함수라고도 부름
- 결과물을 적절한 형식으로 출력하도록 유도해서, 데이터셋과 잘 비교할 수 있도록 하는 역할
- 종류에 제한이 있음(이진분류: 시그모이드, 다중분류: 소프트맥스)
- 은닉층의 활성화 함수
- 여러 겹의 layer들 사이에서 사용됨
- 출력층 함수에 비해 선택이 자유로움
- 대포적인 활성화 함수: ReLU(렐루)
- 모든 신경망의 은닉층에는 항상 활성화 함수가 있음
- 출력층의 활성화 함수
len(np.unique(y_train))
10
# 입력층 - 784개의 특징값
inputs = keras.Input(shape = (784, ))
# 은닉층 - 은닉층의 개수는 데이터의 형태에 맞추지 않아도 됨
dense1 = keras.layers.Dense(100, activation = "sigmoid") # sigmoid: 값을 0~1사이의 값으로 설정해줌
# 출력층 - 범주가 10개
dense2 = keras.layers.Dense(10, activation = "softmax")
- dense1
- 은닉층
- 100개의 유닛을 가진 밀집층
- 유닛 개수를 정하는 것은 특별한 기준이 없음
- 다만 출력층의 유닛보다는 많게 설정하는 것을 추천
- 은닉층의 유닛이 출력층보다 적다면 전달되는 정보량이 부족해질 수 있음
- 활성화 함수는 시그모이드
- dense2
- 10개의 클래스로 분류하므로 10개의 유닛
- 다중 분류이기 때문에 활성화 함수는 소프트맥스
model = keras.Sequential()
- 가장 처음 등장하는 입력층부터 마지막 출력층까지 순서대로 추가해야함
model.add(inputs)
model.add(dense1)
model.add(dense2)
model.summary()

- 모델 요약 정보
- 모델에 포함된 층들이 순서대로 나열됨
- 첫 은닉층부터 출력층까지
- 층마다 이름, 클래스, 출력 크기, 파라미터 개수가 나옴
- 이름
- 층을 만들 때 name 매개변수로 지정 가능(다른 층과 구분하기 위해 이름을 지정)
- 지정하지 않으면 기본값 "dense"
- 이름
- Output Shape
- 출력 크기
- (None, 100)
- 첫 번째 차원은 샘플의 개수를 의미
- 샘플의 개수가 None인 이유는 한 번에 몇 개의 이미지씩 사용할 지 알 수 없기 때문에 어떤 배치 크기에도 유연하게 대응할 수 있도록 None으로 설정
- 케라스는 기본적으로 미니배치 경사하강법을 사용
- batch_size를 설정하지 않으면 기본값 32(48000/1500)
- 두 번째 차원은 출력 개수
- 100개의 유닛에서 결과가 나오기 때문에 출력개수가 100
- 즉, 각 이미지마다 784개의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축됨
- Param
- 모델 파라미터 개수
- dense층
- 784픽셀의 입력값과 100개의 유닛의 모든 조합에 대한 가중치 + 각 유닛의 절편 1개씩
- 784 * 100 + 100 = 78500
- 784픽셀의 입력값과 100개의 유닛의 모든 조합에 대한 가중치 + 각 유닛의 절편 1개씩
- dense_1층
- 앞 은닉층의 100개의 유닛과 10개의 출력층 유닛의 모든 조합에 대한 가중치 + 각 유닛의 절편 1개씩
- 100 * 10 + 10 = 1010
- 앞 은닉층의 100개의 유닛과 10개의 출력층 유닛의 모든 조합에 대한 가중치 + 각 유닛의 절편 1개씩
- Non-trainable params
- 훈련되지 않은 파라미터
- 경사하강법으로 훈련되지 않는 파라미터를 가진 층이 있다면 여기에 표시됨
- 모델에 포함된 층들이 순서대로 나열됨
층을 추가하는 다른 방법
model = keras.Sequential([
keras.Input(shape = (784,)),
keras.layers.Dense(100, activation = "sigmoid", name = "hidden"),
keras.layers.Dense(10, activation = "softmax", name = "output")
], name = "Fashion_MNIST_model")
model.summary()

- 여러 모델과 많은 층을 사용할 때 구분을 위해서 name 매개변수를 사용
모델 훈련
y_train[:5]
array([5, 3, 5, 7, 8], dtype=uint8)
model.compile(loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
model.fit(scaled_train, y_train, epochs = 5, batch_size = 32)

- 은닉층의 추가로 훈련 세트에 대한 성능이 향상됨
시그모이드

- 초창기 인공신경망의 은닉층에서 많이 사용된 활성화 함수는 시그모이드
- 입력값이 아무리 크더라도 0 ~ 1 사이의 값으로 출력되어 출력값의 범위가 너무 좁음
- 경사하강법 수행 시에 기울기가 0에 수렴하는 기울기 소실(Gradient Vanishing)이 발생할 수 있음
- 층이 많아지고 모델이 복잡해질수록 그 효과가 누적되어 더욱 학습을 어렵게 만듦
렐루 함수(ReLU)
- 입력이 양수일 경우 마치 활성화 함수가 없는 것처럼 그냥 입력을 통과시키고, 음수일 경우에는 0이 됨
- 표현식 : max(0, z)
Flatten
- 지금까지는 패션 MNIST 데이터가 28 * 28 크기이기 때문에 인공신경망에 주입하기 전에 reshape를 이용하여 1차원으로 펼쳤음
- 같은 기능을 위해서 케라스에서는 Flatten 층을 제공함
- 샘플의 개수 차원을 제외하고 나머지 모든 입력 차원을 일렬로 펼쳐주는 역할
- 가중치나 절편이 없음
- 하지만 입력층과 은닉층 사이에 추가하기 때문에 편의상 층이라고 부르지만 신경망의 깊이가 깊어진 것으로 보지 않음
model = keras.Sequential()
model.add(keras.Input(shape = (28, 28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
model.summary()
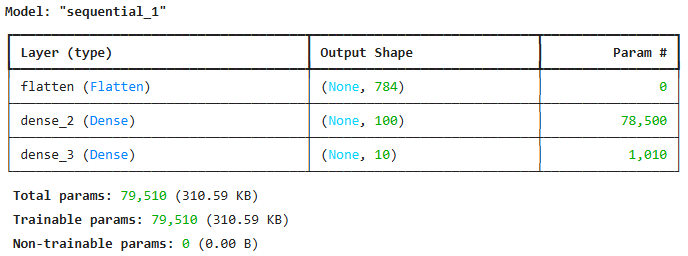
- Flatten 층의 파라미터는 0
- Flatten 층을 추가하면 입력값의 차원을 짐작할 수 있다는 것이 장점
- 784개의 입력이 첫 번째 은닉층에 전달된다는 것이 명확하게 드러남
- 입력 데이터에 대한 전처리 과정을 가능한 한 모델에 포함시키는 것이 케라스 API의 철학 중 하나
새 모델을 위한 데이터를 다시 준비
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
scaled_train = x_train / 255
# Flatten을 했으므로 reshape가 필요 없음 -> reshape없이도 학습이 잘 진행됨
scaled_train, scaled_val, y_train, y_val = train_test_split(scaled_train, y_train, test_size = 0.2,
stratify = y_train, random_state = 26)
scaled_train.shape
(48000, 28, 28)
model.compile(loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
model.fit(scaled_train, y_train, epochs = 5, batch_size = 32)

# 모델 검증
model.evaluate(scaled_val, y_val)

[0.3593044579029083, 0.8735833168029785]
딥러닝의 하이퍼파라미터
- 하이퍼파라미터 : 모델이 학습하지 않아 사람이 지정해줘야하는 파라미터
- 인공신경망에서 하이퍼파라미터의 종류
- 은닉층의 개수
- 은닉층의 유닛 개수
- 활성화 함수
- 층의 종류
- 밀집층, CNN, RNN
- 미니배치 크기(batch_size)
- 반복 횟수(epochs)
- 옵티마이저(optimizer)
- 옵티마이저의 학습률
옵티마이저
- 케라스에서는 기본적으로 경사하강법 알고리즘(RMSprop)을 사용
- 이 외에도 다양한 경사하강법 알고리즘을 제공하고, 이를 옵티마이저라고 부름

# sgd 옵티마이저를 사용하려면
sgd = keras.optimizers.SGD()
model.compile(optimizer = sgd, loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
# 위와 동일한 코드
# ("sgd"로 설정해주면 기본값으로 객체를 자동 생성해줌)
# 원래는 위의 코드처럼 각각의 클래스 객체를 만들어서 사용하는 것이 정석
# 번거로움을 피하기 위해 "sgd"라고 입력하면 자동으로 SGD클래스 객체를 생성해줌
model.compile(optimizer = "sgd", loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
# 옵티마이저의 학습률을 조절하고 싶다면
sgd = keras.optimizers.SGD(learning_rate = 0.1)
옵티마이저의 종류
- Momentum
- SGD 클래스에서 momentum 기본값은 0
- momentum을 0보다 큰 값으로 지정하면 모멘텀 최적화(momentum optimization)을 사용
- 일반적으로 momentum 매개변수는 0.9 이상을 지정
- NAG(Nesterov Accelerated Gradient)
- SGD 클래스의 nesterov 매개변수를 기본값 False에서 True로 바꾸면 네스테로프 모멘텀 최적화를 사용할 수 있음
- 대부분의 경우 네스테로프 모멘텀 최적화가 기본 경사하강법 보다는 더 나은 성능을 제공
# 네스테로프 모멘텀 최적화
nag = keras.optimizers.SGD(momentum = 0.9, nesterov = True)
- 적응적 학습률(adaptive learning rate)
- 모델이 최적점에 가까이 갈수록 학습률을 낮춤
- 안정적으로 최적점에 수렴할 가능성이 높음
- 적응적 학습률을 사용하는 대표적인 옵티마이저
- Adagrad, RMSProp
- 모델이 최적점에 가까이 갈수록 학습률을 낮춤
# Adagrad
adagrad = keras.optimizers.Adagrad()
# RMSprop
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer = rmsprop, loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
- 위의 모멘텀 최적화와 적응적 학습률을 접목한 것이 Adam
- 기본적으로 가장 많이 쓰이는 옵티마이저
model = keras.Sequential()
model.add(keras.Input(shape = (28, 28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
model.summary()

model.compile(optimizer = "adam", loss = "sparse_categorical_crossentropy", metrics = ["accuracy"])
model.fit(scaled_train, y_train, epochs = 5, batch_size = 32)

model.evaluate(scaled_val, y_val)

[0.3450092077255249, 0.8745833039283752]728x90