07_Data_Analysis
10_탐색적 데이터 분석
chuuvelop
2025. 3. 19. 17:31
728x90
탐색적 데이터 분석
(EDA : Exploratory Data Analysis)
- 통찰을 얻기 위한 데이터 분석의 가장 기본이 되는 방법
- 탐색적 데이터 분석의 과정
- 데이터 파악
- 데이터의 외형적인 내용을 파악하는 단계
- raw data : 분석에 활용된 적이 없는, 또는 정제되지 않은 데이터
- 데이터의 출처와 주제 파악
- 데이터가 어디에서 생성된 것 인지
- 데이터가 어떻게 수집된 것인지
- 예) 데이터의 이름, 구성요소, 출처, 주제 등
- 데이터의 크기 파악
- 데이터의 크기에 따라서 데이터의 처리방식이 달라지기 때문에
- 예) 샘플링: 어떤 자료로부터 일부의 값을 추출하는 행위. 데이터가 너무 크거나 전체 데이터를 활용할 수 없는 경우에 수행
- 데이터의 구성 요소(피처) 파악
- 데이터가 어떻게 구성되어 있는지, 어떤 정보를 담고 있는지를 파악하는 아주 중요한 단계
- 예) 신체검사 데이터의 키, 몸무게, 시력, 청력 등
- 데이터의 속성 탐색
- 데이터의 실제적인 내용을 파악하는 단계
- 피처의 속성 탐색
- 피처 속성 탐색 단계에서 가장 중요한 것은 데이터에 질문을 던지는 것
- 예) 우리 반의 평균 키는 몇이나 될까?
- 평균, 표준편차, 중앙값, 사분위 수 등의 통계값을 통해 피처의 정량적 속성을 정의
- 피처 속성 탐색 단계에서 가장 중요한 것은 데이터에 질문을 던지는 것
- 피처 간의 상관 관계 탐색
- 여러 피처가 서로에게 미치는 영향을 알아보는 단계
- 예) 학급이 비만인지 알아보려 했다고 가정하면 몸무게와 관계가 있는 피처를 파악(키)
- 여러 피처가 서로에게 미치는 영향을 알아보는 단계
- 탐색한 데이터의 시각화
- 지금까지 파악한 데이터를 효과적으로 시각화
- 시각화는 수치적 자료만 가지고는 파악하기 힘든 패턴이나 통찰을 발견하는 데에 유용
- 데이터 파악
멕시코풍 프랜차이즈 chipotle 주문 데이터 분석
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt

chipo = pd.read_csv("./data/chipotle.tsv", sep = "\t")
데이터 파악
chipo.head()

# 데이터의 행과 열 파악
chipo.shape
(4622, 5)
# 구성 정보 파악
chipo.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4622 entries, 0 to 4621
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 order_id 4622 non-null int64
1 quantity 4622 non-null int64
2 item_name 4622 non-null object
3 choice_description 3376 non-null object
4 item_price 4622 non-null object
dtypes: int64(2), object(3)
memory usage: 180.7+ KB
chipo.dtypes
order_id int64
quantity int64
item_name object
choice_description object
item_price object
dtype: object
chipo.columns
Index(['order_id', 'quantity', 'item_name', 'choice_description',
'item_price'],
dtype='object')
- 피처의 의미
- order_id : 주문 번호
- quantity : 아이템의 주문 수량
- item_name : 주문한 아이템의 이름
- choice_description: 주문한 아이템의 상세 선택 옵션
- item_price : 주문 아이템의 가격 정보
chipo.describe()

- 간이 분석 내용
- 평균 주문 수량은 약 1.08개 임
- 대부분 한 아이템은 하나만 주문
- 한 사람이 같은 메뉴를 여러 개 구매하는 경우는 많지 않음
- order_id는 숫자의 의미를 갖지 않기 때문에 str로 변환해야 할 수 있음
- item_price는 수치적 특징을 파악해야 하는데 object타입이기 때문에 수치형으로 변환해야함
- 데이터 전처리 필요
- 평균 주문 수량은 약 1.08개 임
# 범주형 피처의 데이터 개수 파악
print(chipo["order_id"].nunique())
print(chipo["item_name"].nunique())
1834
50
데이터 속성 탐색
가장 많이 주문한 아이템 Top 10
chipo["item_name"].value_counts().head(10) # 주문된 횟수/ 주문된 수량 분석가들끼리 기준을 맞춰야함
item_name
Chicken Bowl 726
Chicken Burrito 553
Chips and Guacamole 479
Steak Burrito 368
Canned Soft Drink 301
Steak Bowl 211
Chips 211
Bottled Water 162
Chicken Soft Tacos 115
Chips and Fresh Tomato Salsa 110
Name: count, dtype: int64
아이템별 주문 횟수와 총량
# 아이템별 주문 횟수
order_cnt = chipo.groupby("item_name")["order_id"].count()
order_cnt.head()
item_name
6 Pack Soft Drink 54
Barbacoa Bowl 66
Barbacoa Burrito 91
Barbacoa Crispy Tacos 11
Barbacoa Salad Bowl 10
Name: order_id, dtype: int64
# 아이템별 주문총량(판매량)
item_qt = chipo.groupby("item_name")["quantity"].sum()
item_qt.head()
item_name
6 Pack Soft Drink 55
Barbacoa Bowl 66
Barbacoa Burrito 91
Barbacoa Crispy Tacos 12
Barbacoa Salad Bowl 10
Name: quantity, dtype: int64
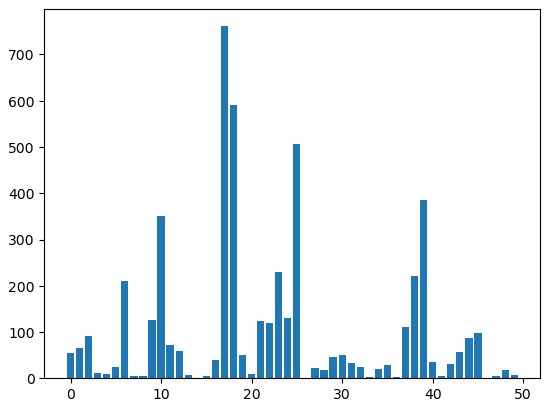
시각화
# item수가 너무 많아서 시각화로 다 나타내기 힘들기 때문에 숫자로 표현
# plt.bar(item_qt.index, item_qt.values)
x_pos = np.arange(len(item_qt))
plt.bar(x_pos, item_qt)
plt.show()
데이터 전처리
item_price 피처 전처리
chipo["item_price"].head()
0 $2.39
1 $3.39
2 $3.39
3 $2.39
4 $16.98
Name: item_price, dtype: object
- 원인
- 가격을 나타내는 숫자 앞에 $ 기호가 붙어 있음
float("$2.39") # 달러기호 때문에 float로 변환이 안됨
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[37], line 1
----> 1 float("$2.39")
ValueError: could not convert string to float: '$2.39'
chipo["item_price"].map(lambda x: float(x[1:]))
# chipo["item_price"].str[1:].astype(float)
# chipo["item_price"].str.replace("$", "").astype(float)
# chipo["item_price"].str.split("$").str[1].astype(float)
chipo["item_price"] = chipo["item_price"].map(lambda x: float(x[1:]))
chipo.head()
chipo.dtypes # item_price 가 float64로 바뀜을 확인
chipo.describe()
데이터 탐색
주문당 평균 계산금액
chipo.groupby("order_id")["item_price"].sum().mean()
- 한 사람이 약 19달러 가량의 주문을 할 것으로 예상됨
한 주문에 30달러 이상 지불한 주문
- order_id를 기준으로 그룹화
- item_price의 합계를 기준으로 필터링
order_group = chipo.groupby("order_id").sum()
order_group
order_group[order_group["item_price"] >= 30]
각 아이템의 가격 구하기
- 현재 아이템 데이터는 없기 때문에 아이템의 가격을 구하기 위해서는 주문 데이터에서 유추하는 방법밖에 없음
- 동일한 아이템을 1개만 구매한 주문을 선별
- item_name을 기준으로 그룹화한 뒤 각 그룹별 최저가를 계산
# 1. 동일한 아이템을 1개만 구매한 주문을 선별
one_item = chipo[chipo["quantity"] == 1]
one_item.head()

# 2. item_name을 기준으로 그룹화한 뒤 각 그룹별 최저가를 계산
item_price = one_item.groupby("item_name").min()
item_price

...
# 정렬
item_price.sort_values("item_price", ascending = False)
...
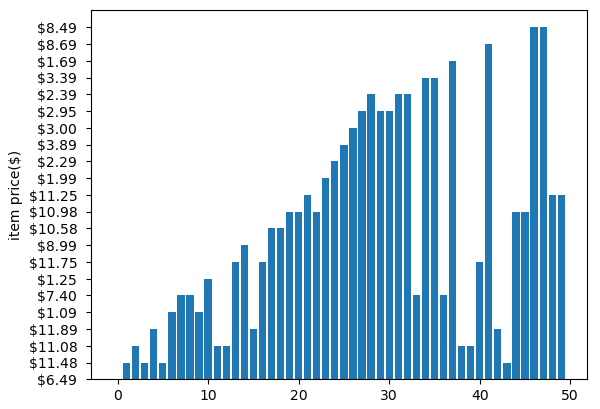
# 아이템 가격 시각화
x_pos = np.arange(len(item_price))
plt.bar(x_pos, item_price["item_price"])
plt.ylabel("item price($)")
plt.show()
# 아이템 가격 히스토그램
plt.hist(item_price["item_price"])
plt.ylabel("counts")
plt.show()

가장 비싼 주문은 총 몇개의 아이템을 주문하는지 파악
chipo.groupby("order_id").sum().sort_values("item_price", ascending = False).head()
chipo[chipo["order_id"] == 926]

Veggie Salad Bowl이 몇 번 주문되었는지 파악
salad_df = chipo[chipo["item_name"] == "Veggie Salad Bowl"]
salad_df.head()

salad_df.shape
(18, 5)
salad_df["quantity"].sum()
18
Chicken Bowl 을 2개 이상 주문한 고객들의 Chiken Bowl 메뉴에 대한 총 주문 수량 구하기
chicken_df = chipo[chipo["item_name"] == "Chicken Bowl"]
chicken_df.head()
group_chicken = chicken_df.groupby("order_id")["quantity"].sum()
group_chicken.head()
order_id
2 2
3 1
7 1
10 1
13 1
Name: quantity, dtype: int64
result = group_chicken[group_chicken >= 2]
result.head()
order_id
2 2
34 2
70 2
93 2
124 3
Name: quantity, dtype: int64result.sum()
260728x90